
Monorepo: Hands-On Guide for Managing Repositories and Microservices
Managing large monorepos can be a daunting task. This guide will walk you through the considerations and the steps involved in managing a large repository.

TL;DR
- Monorepos group multiple microservices and libraries into a single repository, enabling atomic commits, easier large-scale refactors, and shared tooling but introduce challenges in build times, CI/CD scaling, and code review complexity.
- Tools like Bazel, Nx, and Turborepo help manage builds, cache results, and speed up pipelines, making monorepos practical even at large scale.
- Best practices include modular project structure, strict code ownership rules, dependency graphs to isolate changes, and using selective build/test pipelines to avoid slow full builds.
Monorepos support cross-service refactors and consistent linting/testing, while polyrepos allow service-level autonomy, smaller repos, and independent deployment cycles. - Migration isn’t trivial: consolidating repos can break existing CI/CD, create merge conflicts, and require new tooling so gradual adoption, automated checks, and clear ownership policies are essential to keep teams productive.
The biggest challenge for a developer working on a large project with many components or services is managing a codebase with several tech stacks and framework dependencies. Maintaining a clear sense of ownership among team members for each component is also essential to ensuring accountability and effective growth.
A Monorepo can address these problems by putting everything into a shared repository. Teams can enforce uniform procedures and shared libraries and monitor changes throughout the codebase using this configuration. This monorepo structure facilitates code organization, dependency management, and compatibility testing, which makes it easier for developers to collaborate and uphold accountability. This strategy is used by even major tech firms like Google and Facebook to handle their extensive projects efficiently.
Depending on your particular use case, we will go into great detail on what Monorepos are, how they operate, and the many build tools you may use for your projects. We will also go over the difficulties of dealing with a monolithic repository and walk you through a practical sample project so you can grasp how to use a Monrepo and incorporate it into your workflow.
What are Monorepos
A monorepo is a single repository with several separate services, modules, or components, some of which may have been developed using a different framework or language.
Exempli Gratia: Take the example of a large e-commerce site where the user interface is build in React, the backend services is built in with either Python or Node.js, and a product recommendation system uses a machine learning model made in python. Now imagine all these have their own files in a monorepo. By keeping everything in one place, this setup facilitates the coordination of updates, the sharing of common dependencies, and the incident-free monorepo management of changes throughout the whole system.
This stability in a Monorepo code structure is maintained by a single-build tool that maintains all projects, ensuring overall consistency and efficiency. Meanwhile, a Polyrepo or multiple repository approach frequently relies on multiple build tools, each tailored to the individual services or APIs, giving teams flexibility but resulting in inconsistent configurations such as repositories with different versions of the same dependency, as well as varying code standards and linting rules.
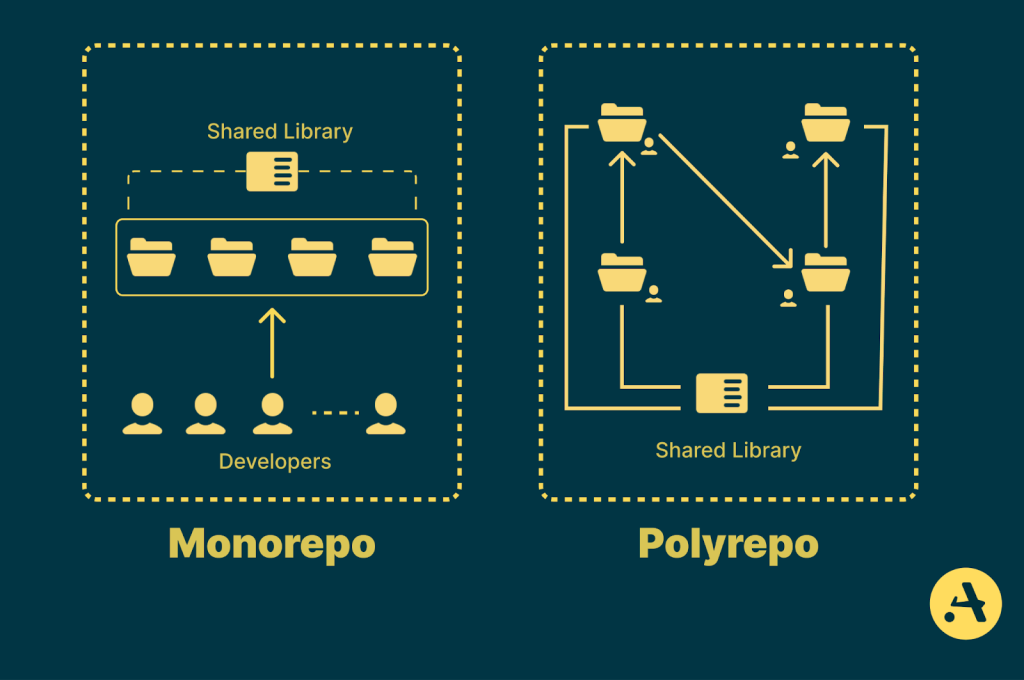
A monorepo’s unified directory structure, where related code is organized in shared folders, contrasts with a polyrepo’s isolated project setup, where each project operates independently.
Create polyrepo architecture which come with specific challenges, especially when it comes to sharing code across projects. Managing dependencies can be complicated since they often require maintaining separate repos or shared libraries. While this approach can offer flexibility, it also has downsides, like difficulties in version control and collaboration as projects grow. Knowing these factors helps choose the best setup for managing large projects effectively.
Similarly, in a monorepo, strict conventions and thorough testing are needed to prevent issues when project changes occur. As the monorepo grows, managing scalability can also become challenging, especially with larger teams and multiple projects, but this isn’t as much of an issue in polyrepo setups.
For additional context on the background and evolution of Monorepos, check out Aviator’s blog here, which analyzes Monorepo and why you should use one for your projects.
How to Manage Microservices in Monorepo
So far, we know that a monorepo directory structure makes collaboration easier because teams don’t need to switch between separate repositories to find the features they’re working on. Instead, everything is organized in one place, with clear folder structures for each project or service.
Let’s say you’re working in a team with a Python project folder for backend monorepo services and a JavaScript folder for the frontend and dashboard, which require regular updates and fixes to keep them running smoothly. In a monorepo, each service is organized within its folder, but everyone can see the code structure at once. This setup makes it easy for teams to share utility libraries, keep updates consistent across services, and avoid redundancy. For example, if a shared configuration or API client needs to be updated, all services can access the latest version simultaneously.
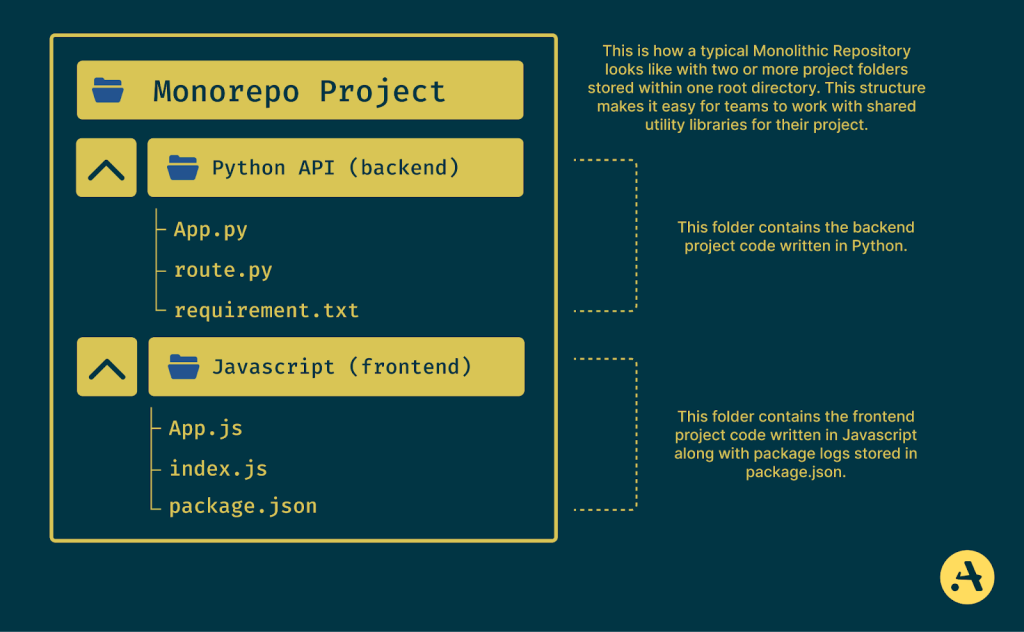
For example, if multiple projects use the same authentication library, such as JSON web tokens, OAuth, and AWS Cognito SDK, monorepo allows teams to update or improve this library in one location, instantly applying those changes across all projects that rely on it. This reduces duplication and keeps code consistent throughout the system.
Monorepos also helps with dependency management. Rather than each project handling its dependencies, which can lead to dependency version conflicts, a monorepo keeps all dependencies in one place, ensuring that compatible versions are used across projects. This setup minimizes the risk of dependency issues and simplifies updating libraries, as all projects are built and tested with identical dependency versions.
Another significant benefit is having a single CI/CD pipeline. It’s not like you can’t use CI/CD pipelines with polyrepos as well. Still, In a monorepo, you can set up one continuous integration and delivery process to automatically test, build, and deploy changes across all services under the same pipeline otherwise, you need to take care of multiple pipelines for multiple services. This unified pipeline saves time and reduces complexity, as you don’t need to create and maintain separate pipelines for each project. With a single source of truth for building and deploying code, developers can track changes more efficiently and keep everything in sync, which is crucial for maintaining efficiency in larger projects.
Difficulties in Managing Microservices within a Monorepo
As discussed above, microservices in monorepo is a better choice if you deal with multiple projects simultaneously. But, one should also be aware of the challenges you may face while working with monorepos as managing a monorepo comes with its own set of issues.
Complex Setup
Monorepos are known for having Complex Setup, as getting each consumer project running locally can be daunting, often requiring you to navigate outdated documentation, fix database issues, and manage feature flags, among other setup challenges.
Dependency Management
Another significant issue is dependency management. Now, we have discussed above how Monorepo helps to mitigate dependency version conflicts for us, and that gives it a substantial edge over polyrepos. Still, since all code is in one place, it also becomes easy for dependencies to overlap, causing conflicts or even breaking projects.
Additionally, large monorepos code bases can lead to tightly coupled code, where changes in one service affect others, making updates more complex. This coupling often requires strict conventions to keep code modular and avoid unintended dependencies across projects.
Too Many Commits in a Single Repository
A high number of commits in one repository can slow down Git operations like git log and git blame since Git has to handle an extensive history of changes. This can make the repository sluggish, mainly as more projects and developers contribute to the same repo.
Performance Bottlenecks
Performance issues also arise, particularly with the number of tracked commits, branches, and files. A large volume of commits can slow down operations like git log or git blame, as Git has to navigate a complex history graph. With many unrelated projects in a single repository, performance can degrade significantly.
Testing Hurdles and Optimizing the CI/CD Pipeline
Running tests, builds, and deployments for a large monorepo can become slow and resource-heavy, especially as the codebase grows. Many monorepos lack adequate code coverage, making testing changes thoroughly difficult. If you’re responsible for breaking changes, you might need to test numerous dependent projects, which can be time-consuming manually.
To keep things efficient, teams often need automated pipelines to run selective builds only for affected parts of the code, saving time and resources. Using a modern build system like Bazel or Gradle can help managing remote caching and perform an affected targets based distributed tests.
Modular configurations are also recommended, which structure configurations by projects or services within a monorepo, allowing each module or service to maintain its settings while remaining part of the shared repository. This eventually helps keep monorepos manageable at scale.
Code Ownership
As we often hear the phrase, “Too many cooks in the kitchen can burn the food”. This also proves true for developers when working on large monorepos. Since a monorepo encourages shared ownership, setting clear guidelines for code contributions and review processes is critical. Without this, projects can quickly become messy, and it’s easy for technical debt to build up. By implementing CI/CD pipelines, version control, and consistent coding standards, teams can stay organized and avoid many challenges.
Build Tools for Managing Monorepos
Monorepo tools are a significant part of what makes the monorepos operational. Without them, managing the projects, dependencies, build control, and version control can become manageable.
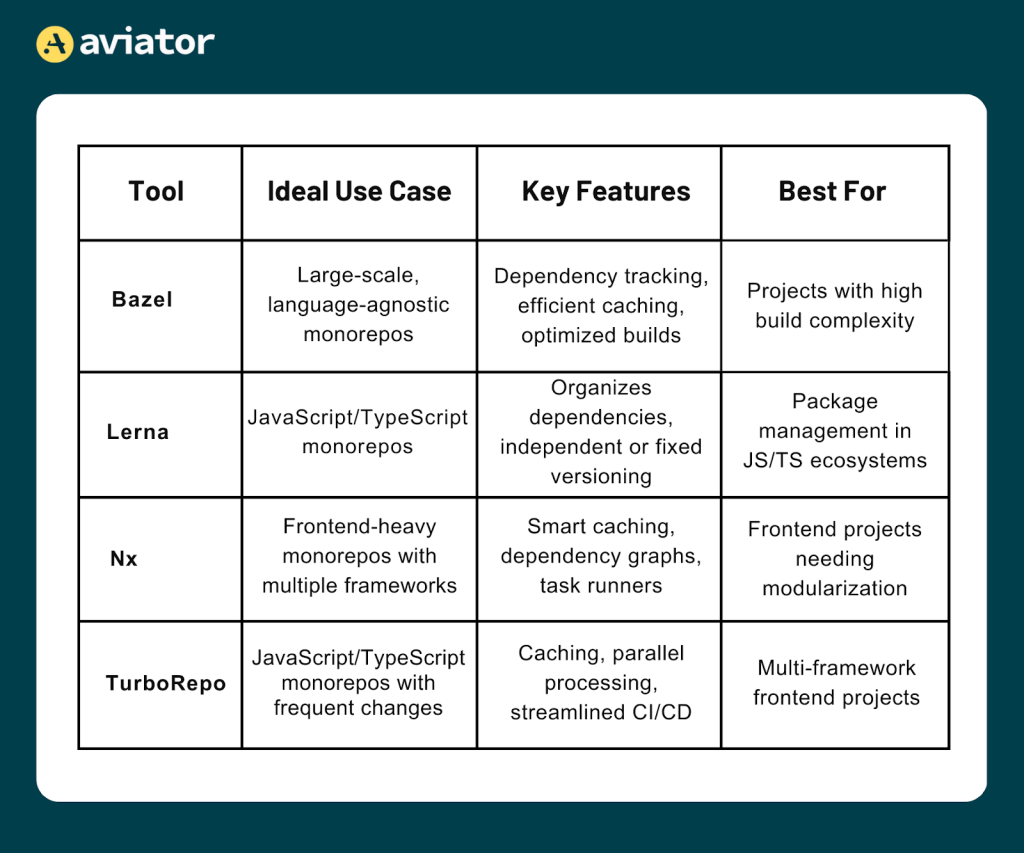
For monorepos containing multiple frontend frameworks, TurboRepo and Nx optimize performance with features like intelligent caching and incremental builds, speeding up development cycles. They excel in managing dependencies and maintaining consistent configurations, reducing redundancy, and minimizing build times. This ensures frontend components remain compatible and up-to-date across the repository.
Bazel and Buck2 are ideal for managing services and libraries for backend systems. Bazel supports parallel execution, remote caching, and a robust dependency system, reducing redundant builds and speeding up processes. Buck2 focuses on fine-grained caching and efficient dependency tracking, offering faster incremental builds and lower storage needs, especially for large, complex codebases.
When to Use a Monorepo
Some of the most common and well-known applications include:
Microservices Architecture
In a microservices setup, each service handles a specific function within a more extensive application, such as user management, payments, or notifications. Managing these in a monorepo enables developers to keep all related services in one place, making it easier to share code, such as standard authentication modules or utility functions.
For example, if a change is made to the authentication logic, teams can immediately update all services that depend on it, maintaining consistency across the system without needing to track changes across multiple repositories.
Cross-team Collaboration
Monorepos improves team collaboration as all the code is centralized. It allows teams to easily access, review, and integrate changes from other services. This setup reduces interference to cross-team code sharing and consistency, which is especially useful for enterprises managing multiple services or APIs.
For instance, a frontend and backend team working on the same application can easily align and coordinate changes. This avoids the challenges of merging code from separate repositories and ensures a more seamless development process across project boundaries.
Rapid Development Cycles
For teams focusing on rapid development cycles, monorepos enable faster updates by centralizing the codebase and making managing changes across projects easier.
For example, if an organization frequently updates its app with new features, a monorepo setup allows changes to be implemented across the system more efficiently without the overhead of navigating multiple repositories. The ability to run a single, unified CI/CD pipeline further streamlines the process, speeding up testing deployment and ensuring all components remain compatible.
Hands-on Example with Bazel
Now, to get a better understanding of how you can create a Monorepo with two or more services and with a mainstream build tool, we will go through a hands-on example of where we will be making a root directory, and within it, we will have a frontend project created using react project, and a backend project created using Flask in Python.
Build tools like Bazel and Turborepo ensure smooth codebase growth by handling builds and dependencies efficiently. They rebuild only changed parts of the code, preventing slowdowns as the codebase expands. By enforcing consistent build rules, they maintain compatibility across projects, making adding new features or services easier without delays or clutter.
We will use Bazel as the build tool for this demonstration, as it is pretty versatile and compatible with most tech stacks.
Installing Bazelisk
We first need to install Bazelisk on our development machine to get started. Bazelisk is a version manager for Bazel, much like how Python Version Manager (pyenv) and Node Version Manager (nvm) work.
Follow the installation instructions on Bazelisk’s official github repository to install it on your machine, or you can also use Bazelisk’s Releases page to install it for your desired operating system.
After your installation is completed, you can run the following command to check your Bazel version:
baselisk --versionSetting Up the Root Directory
We will now set up our mono repository structure. For this, we will now create a folder called “Monorepo-demo”. You can name it as per your preference.
mkdir Monorepo-demoNext will create two more folders inside the root monorepo directory, the first one will be for the backend service which we will be running on Python and the second one will be for a frontend service which we will be creating using React.js.
cd Monorepo-demo
mkdir backend-python
mkdir frontend-reactThe folder structure will look something like this:
.
├── backend-python
└── frontend-react
Now, we have taken the first step towards creating a monolithic repository.
Creating a React Application
We will now start with the setup and configuration of our react project. First of all, we need to navigate to the React project directory to install the Create React App Template (CRA).
cd frontend-reactNow, for the following step to work as intended, ensure you have installed Node.js on your machine. You can check Node’s version using the following command:
node -vTo use Bazel, we need to define “rules.” These rules are essential to Bazel and determine how projects or services are built within the monorepo. Rules allow Bazel to incorporate new tools for creating and testing different languages and frameworks, making them a crucial part of Bazel’s functionality.
For React.js, we will be using Aspect’s Rules. These rules are third-party helper rules written by engineers at Aspect Build. They are open-sourced and are recommended by Bazel’s community themself.
Also, one thing to note is that Aspect’s Rules for javascript have been created to be used with the pnpm package manager. So, for this demonstration, we will work with pnpm as our default package manager. You can read more about why Aspect uses pnpm here.
To use pnpm, simply use the following command:
npm install --global pnpmThis command will install pnpm globally on your machine so that you can access it from any folder.
Now, we will install the Create React App template using the following command:
pnpm create react-app .This will create your React starter project folder it will look something like this:
.
├── node_modules
├── package-lock.json
├── package.json
├── public
├── README.md
└── src
You can use the start script to check if your react app is running successfully:
pnpm startCompiled successfully!
You can now view frontend-react in the browser.
http://localhost:3000
Note that the development build is not optimized.To create a production build, use npm run build.
webpack compiled successfully
Creating Bazel Configuration Files
Now that the Monorepo file structure and React application setup are complete. We can move forward and create our Bazel Workspace configuration files, which Bazel would need to generate a build for the applications.
First of all, we will create a file named WORKSPACE. This file is responsible for defining dependencies and handling modules within the project. But, in the latest version of Bazel, the approach has shifted to using MODULE.bazel as the main configuration file for defining dependencies and managing the project’s external modules. An important point to note is that WORKSPACE is still required, even if blank, for backward compatibility within the project structure.
We will also create a BUILD.bazel file to define the build constraints in the monorepo directory.
Next, we wil define the workspace Bazel configuration in the .bazelrc file.
.bazelrc
common --enable_bzlmod
build --enable_runfilesIn this .bazelrc setup, common –enable_bzlmod turns on Bazel’s new system for managing dependencies, called bzlmod, for all commands. This change means Bazel will use the MODULE.bazel file instead of the older WORKSPACE file, which helps organize dependencies more straightforwardly. The build –enable_runfiles line ensures that Bazel includes runfiles when building on Windows. This is important for rules like rules_js, which need access to specific files to run correctly. Enabling runfiles here ensures everything works smoothly on Windows, where runfiles aren’t always set up by default.
Now, to let Bazel configure a workspace in a project managed by pnpm, we will list those project directories in the pnpm-workspace.yaml file.
pnpm-workspace.yaml
packages:
- frontend-reactWith the PNPM workspace folders defined, we need to create a package.json file to handle configurations specific to the PNPM package manager and manage missing dependencies.
package.json
{
"name": "test-monorepo",
"version": "0.1.0",
"dependencies": {
"react": "^18.2.0",
"react-dom": "^18.2.0",
"react-scripts": "5.0.1",
"web-vitals": "^2.1.4"
},
"devDependencies": {
"@types/react": "^18.2.15",
"@types/react-dom": "^18.2.7",
"eslint": "^8.45.0",
"eslint-plugin-react": "^7.32.2",
"eslint-plugin-react-hooks": "^4.6.0",
"eslint-plugin-react-refresh": "^0.4.3"
},
"pnpm": {
"//packageExtensions": "Fix missing dependencies in npm packages, see https://pnpm.io/package_json#pnpmpackageextensions",
"packageExtensions": {
"@typescript-eslint/eslint-plugin": {
"peerDependencies": {
"eslint": "*"
}
},
"postcss-loader": {
"peerDependencies": {
"postcss-flexbugs-fixes": "*",
"postcss-preset-env": "*",
"postcss-normalize": "*"
}
}
}
}
}We will now configure the project module for this Bazel repository with the MODULE.bazel file.
MODULE.bazel
module(name = "test-monorepo", version = "1.0")
#javascript
bazel_dep(name = "aspect_rules_js", version = "1.32.5")
####### Node.js version #########
# By default you get the node version from DEFAULT_NODE_VERSION in @rules_nodejs//nodejs:repositories.bzl
# Optionally you can pin a different node version:
bazel_dep(name = "rules_nodejs", version = "5.8.2")
node = use_extension("@rules_nodejs//nodejs:extensions.bzl", "node")
node.toolchain(node_version = "16.14.2")
#################################
npm = use_extension("@aspect_rules_js//npm:extensions.bzl", "npm", dev_dependency = True)
npm.npm_translate_lock(
name = "npm",
bins = {
"react-scripts": [
"react-scripts=./bin/react-scripts.js",
],
},
data = [
"//:package.json",
"//:pnpm-workspace.yaml",
"//:frontend-react/package.json",
],
npmrc = "//:.npmrc",
pnpm_lock = "//:pnpm-lock.yaml",
verify_node_modules_ignored = "//:.bazelignore",
update_pnpm_lock = 1,
)
use_repo(npm, "npm")
bazel_dep(name = "aspect_bazel_lib", version = "1.35.0")
pnpm = use_extension("@aspect_rules_js//npm:extensions.bzl", "pnpm", dev_dependency = True)
use_repo(pnpm, "pnpm")In the MODULE.bazel file, we define the project module for Bazel, managing dependencies for the monorepo named test-monorepo with version 1.0. It includes the aspect_rules_js dependency (v1.32.5) to set up JavaScript build rules and rules_nodejs (v5.8.2) to ensure Node.js support, specifically using version 16.14.2.
The file then imports the NPM extension from aspect_rules_js, treating it as a development dependency. This translates the package.json and lock file for Bazel and links necessary scripts like react-scripts. It also registers aspect_bazel_lib (v1.35.0) for additional Bazel tools and the pnpm extension as a dev dependency to complete the setup. This configuration organizes dependencies and keeps JavaScript tools in sync across the monorepo.
Remember the BUILD.bazel file, did we create it in the root directory? We’ll use it to link all necessary packages, including the workspace’s NPM packages, packages from the Bazel binary, and the virtual store for aspect_rules_js. This setup works because pnpm-lock.yaml is at the root of the pnpm workspace, allowing us to manage dependencies effectively.
BUILD.bazel
load("@aspect_rules_js//js:defs.bzl", "js_binary")
load("@npm//:defs.bzl", "npm_link_all_packages")
npm_link_all_packages(
name = "node_modules",
)This snippet loads two Bazel rules to manage JavaScript packages. The js_binary rule from aspect_rules_js is loaded first, which allows us to create runnable JavaScript files within the project.
Then, npm_link_all_packages from the npm dependency is loaded and calls the node_modules, linking all npm packages from package.json into Bazel. This setup ensures all Node.js dependencies are accessible within the Bazel environment, keeping everything organized and ready to use.
Creating the Build File for React Application Folder
We have set up the entire workspace to work with Bazel. All we need to do is create a BUILD.bazel file in the React project folder so that Bazel can build the frontend.
frontend-react/BUILD.bazel
load("@aspect_rules_js//js:defs.bzl", "js_run_devserver")
load("@npm//:defs.bzl", "npm_link_all_packages")
load("@npm//:react-scripts/package_json.bzl", cra_bin = "bin")
npm_link_all_packages()
CRA_DEPS = [
"//packages/my-app/src",
"//packages/my-app/public",
":node_modules/react-dom",
":node_modules/react-scripts",
":node_modules/react",
":node_modules/web-vitals",
":package.json",
]
cra_bin.react_scripts(
# Note: If you want to change the name make sure you update BUILD_PATH below accordingly
# https://create-react-app.dev/docs/advanced-configuration/
name = "build",
srcs = CRA_DEPS,
args = ["build"],
chdir = package_name(),
env = {"BUILD_PATH": "./build"},
out_dirs = ["build"],
)
js_run_devserver(
name = "start",
args = ["start"],
chdir = package_name(),
command = "node_modules/.bin/react-scripts",
data = CRA_DEPS,
)This code sets up Bazel to build and run a Create React App (CRA). It loads js_run_devserver to run a local server, npm_link_all_packages to link npm packages, and react-scripts commands for CRA.
First, npm_link_all_packages() makes npm dependencies available to Bazel. The list CRA_DEPS includes source files, public files, and essential npm packages for the app. Then, cra_bin.react_scripts runs react-scripts build to build the app, with output in the build folder. Finally, js_run_devserver starts the app in development mode using react-scripts start, allowing you to test the app locally. This setup keeps build and run steps organized within Bazel.
Before we can build out the application, one last thing to do is prevent npm from “hoisting” dependencies to the root node_modules folder.
.npmrc
hoist=falseNow, we are all set to build or run the React application. To Build the application, use the following command:
bazel run //frontend-react:buildTo start the development server, use the following command:
bazel run //frontend-react:startCreating a Flask Application
Now, just like the frontend, we will need to set up our backend for Bazel as well.
Navigate to the backend folder using the following command:
cd ../backend-pythonFor starters, we would create a simple flask application to display a message on our development server. To do this, you must first ensure that you have Python version 3 installed on your machine.
After that, install the flask dependency on your machine using the pip:
python -m pip install flaskOnce the flask command is installed, we will make a requirement.txt and an App.py file in the backend-python folder:
requirement.txt
Flask==2.0.2App.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Backend with Flask on a Monorepo!'We will run the Flask app to start the development server and check if the backend works.
python -m flask --app ./App.py runThis command will start your development server at port 5000, and you can access it from http://localhost:5000/.
Since we are done with the basic structure of our backend, we can now start configuring it to work with Bazel.
Configuring Build File for Python
Since we have taken care of most of the workspace configuration files above, we just need to create a BUILD.bazel file in the Python project directory, and make some changes to the MODULE.bazel file to accommodate Python.
BUILD.bazel
load("@python_deps//:requirements.bzl", "requirement")
py_binary(
name = "main",
srcs = ["main.py"],
deps = [
requirement("Flask")
],
)The main program here is defined using the py_binary function in this Bazel configuration. This program uses main.py as its source file, which contains the main logic for execution. Additionally, it specifies a dependency on the Flask web framework through the requirement function, ensuring that Flask is automatically included during the build process. This setup allows for efficient management of dependencies and organization of the Python project within Bazel.
Now, add the following line to your MODULE.bazel file.
MODULE.bazel
bazel_dep(name = "python_deps", version = "3.9.0")This adds Python as a dependency that Bazel manages.
To run this, simply use the following command:
bazel run //backend-python:mainUsing Backstage for Managing Monorepos
Backstage provides a streamlined way to organize and manage a monorepo by centralizing all code components, services, and libraries into a catalog. With the catalog service, you can use a single catalog for the entire repo or split it into individual projects, depending on team structure and how tightly components are connected. One catalog entry is sufficient for a single-team setup where everything is interdependent. This keeps things simple and centralizes all dependencies and relationships in one place.
For larger setups with multiple teams managing different parts of the monorepo, dividing the catalog helps by allowing each team to control its entry. This approach ensures that each project or service has its catalog-info.yaml file, simplifying updates, dependency tracking, and customization for specific needs without overwhelming a single catalog file.
Developer Portal for Documentation and Navigation
One of Backstage’s most robust features is its TechDocs integration, which makes documentation accessible directly within the portal. Instead of sifting through separate documentation sources, Backstage docs makes it easy to find detailed, context-specific information while navigating the catalog.
TechDocs allows documentation for each component or service in markdown format. The portal also allows quick access to dependencies and critical project information, creating a more efficient workflow across projects and enabling new team members to get familiar with the repo faster. However, managing internal developer portals can be a tedious task.
CI/CD Pipeline Management
Backstage can connect with various CI/CD tools (like Jenkins and GitHub Actions), providing a single interface to monitor all builds, tests, and deployments across the monorepo. Teams can view ongoing builds, trigger tests, or review deployment logs within Backstage, offering clear visibility into how each project is performing. This visibility is invaluable in a monorepo setup, where multiple services often rely on shared resources and dependencies. It is essential to catch issues early before they cascade through the codebase.
Dependency Management and Change Tracking
Backstage’s dependency tracking helps teams see relationships and dependencies between different parts of the monorepo. For instance, when a component or library is updated, Backstage provides insights into any other components that might be affected. This helps avoid unexpected issues from code changes, as developers can evaluate the impact of each update.
To set up a monorepo effectively, consider a split catalog if multiple teams own parts of the code. For centralized CI/CD and simplified deployment visibility, it is recommended to integrate Backstage with your pipelines to get a clear overview of your deployments and services in one place.
What are the Best Practices for Managing Dependencies in a Monorepo
Organizing Code
Organizing code effectively in a monorepo is essential for smooth collaboration and scalability. A good structure should separate different projects or services into distinct folders, ideally following a logical hierarchy that mirrors the system’s architecture.
Strict linting rules can be enforced to ensure coding standards across the monorepo. Setting up tools like ESLint with custom rules tailored for monorepos helps detect issues early and keeps code consistent. Automated code formatters like Prettier maintain a uniform style throughout the codebase, essential when multiple teams contribute to the same repository.
Efficient Deployments
Automating deployments is crucial in monorepos, where individual services or components may need to be deployed independently. Tools like Aviator Releases are beneficial for handling these deployments. They allow for coordinated, automated releases of different parts of the monorepo, enabling teams to roll out updates without manually deploying each component. With this setup, you can deploy updates in a way that minimizes downtime and reduces the risk of errors.
Distributed Merge Queue
Managing code merges in a monorepo can become challenging as multiple teams work on different parts of the codebase. Aviator MergeQueue, combined with selective targeting, helps manage these merges more efficiently. By only merging the parts of the code that are affected by specific changes, Aviator allows distributed merges, minimizing conflicts and reducing waiting time for other teams. This setup keeps code integration smooth and avoids unnecessary bottlenecks.
You can learn more about merge queues here.

Dependency Management
Centralizing dependencies in a monorepo is essential for preventing “dependency drift,” where different parts of the code use incompatible versions of the same library. Using version constraints and automated update tools aligns dependencies across all projects, ensuring compatibility and stability. Setting up a central dependency file and automating updates ensures that libraries are always up-to-date, saving time and avoiding compatibility issues.
Ensuring Backward Compatibility
Backward compatibility is essential in a shared codebase, as updates to one service or library could impact other system parts. Use semantic versioning and transparent deprecation practices to avoid breaking changes. Isolated testing of updates is also critical, allowing teams to verify that changes won’t disrupt other services. This practice helps maintain a stable system and minimizes the risk of unexpected issues.
Horizontal Migrations
Horizontal migrations can be challenging to coordinate across multiple teams in a monorepo. By defining the scope of the migration and using incremental updates, teams can minimize the impact on the system. Automation tests help detect issues early, and fallback strategies are essential for rolling back in case of any problems. This approach keeps migrations manageable and ensures stability.
Codeowners Support for Monorepos
In monorepos, assigning code ownership helps teams understand who is responsible for different parts of the code. GitHub’s Codeowners file lets you specify ownership using wildcards to match directories or files. This setup streamlines code review processes by automatically routing changes to the appropriate team members.
For more guidance, check out Aviator’s blog, which explains Codeowners and provides a better understanding of how to get started and incorporate Codeowners into your services.
Conclusion
The monorepo approach offers significant advantages for managing large-scale projects and monorepo microservices architectures. By consolidating all code into a single shared repository, developers can benefit from improved collaboration, consistent dependency management, and streamlined CI/CD pipelines. While there are challenges to overcome, such as complex setup, performance considerations, and team management, the long-term benefits of a monorepo often outweigh the initial hurdles.
As demonstrated in the hands-on example, tools like Bazel, Lerna, Turborepo, and Nx can greatly facilitate the management and scaling of a monorepo, providing features like intelligent caching, incremental builds, and modular configurations.
By adopting best practices around code organization, deployment automation, and dependency management, teams can effectively leverage the power of a monorepo to build efficient and scalable software systems. Overall, the monorepo model has proven its value in the industry and is a compelling choice for organizations seeking to improve collaboration, consistency, and productivity across their codebase.

FAQ
Does Google Use a Single Repo?
Google’s monolithic repository provides a common source of truth for tens of thousands of developers worldwide. Early Google employees decided to work with a shared codebase managed through a centralized source control system.
Is Monorepo a Good Idea?
One of the most compelling benefits of a monorepo is its ability to simplify version control. In a traditional multirepo setup, each project or component has its repository, often leading to versioning conflicts and making it difficult to keep track of changes across projects.
What is the Difference Between Monorepo and Monolithic?
A Monorepo is a version control strategy where multiple projects reside in a single repository but can be independently developed and deployed. A Monolithic architecture, on the other hand, is a tightly integrated application where all components are built and deployed together. Monorepo is about code organization, while Monolithic is about application structure.
Where to Deploy Monorepo?
A monorepo can be deployed on platforms like GitHub, GitLab, Bitbucket, Google Cloud Source Repositories, or AWS CodeCommit. For efficient builds and CI/CD, tools like Bazel, Nx, Turborepo, and Jenkins help manage deployments effectively.








