How Git compresses files
In this article, we will dive into the Git internals and see how files are actually compressed and stored there.
Git stores the files efficiently by only storing the differences, but how does it actually work? Naively, we can think of the git diff output and storing it.
This is not the case. Let’s look at how things actually work.


Compressing one file
Let’s start with a simple scenario; there is only one file in the repository. We modify that file and make a commit. Now there are the current and previous versions of that file. If we were a Git-core developer, how can we store these two versions of a file efficiently?
A naive approach is taking a diff of these two files. If we keep a full copy of the file v1 and a diff output between the file v1 and the v2, we do not need a full copy of the file v2. In order to rebuild the file v2, we can apply the patch to the file v1.
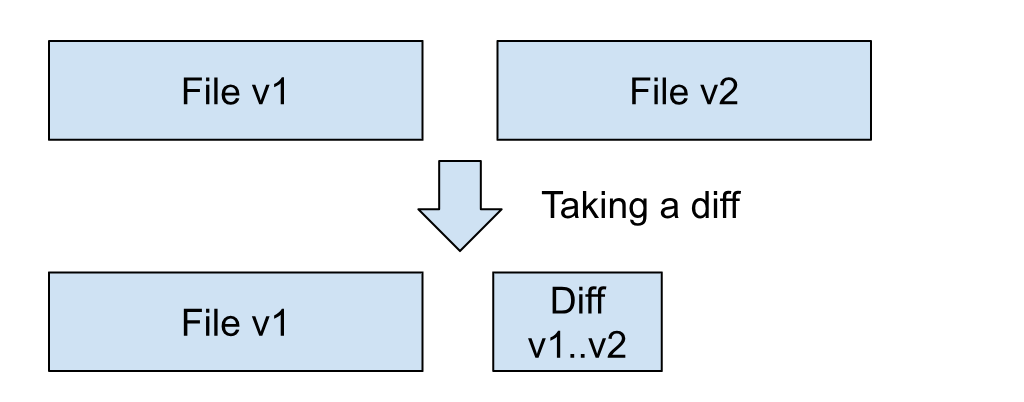
This works, and it is conceptually what Git does. However, Git is not simply using the diff command to calculate the diffs.
Instead of using the diff output, Git has its own format. This format is a sequence of two commands:
- Copy: Takes an offset and a length. Copies a byte sequence from the file v1 at the specified offset
- Write: Takes a byte sequence. Insert the specified sequence
This command sequence is instructions on how to recreate the file v2. Given the file v1, if you follow these commands, you can get the file v2. This is well explained and visualized in the GitHub blog (https://github.blog/2022-08-29-gits-database-internals-i-packed-object-store/#delta-compression).
Now the question is how to create this sequence from the file v1 and v2. Git uses the rolling hash to find out the similarity.
- Split the file v1 into small chunks, and take a hash of them. You can construct
Map<HashCode, List<Offset>>, where the key is the calculated hash and the value is a list of the file offset of the chunks with that hash code. - Read the file v2 from the beginning. Take the same-sized chunk and hash it. With the table created in the previous step, you can get the file v1’s offsets that can have the same chunk. You can go over those offsets, and find the longest common sequence between this file v1 and v2 for this portion of the file. Output the copy command to the diffing output. If you cannot find a common sequence, you can use the write command, and continue to the next byte.
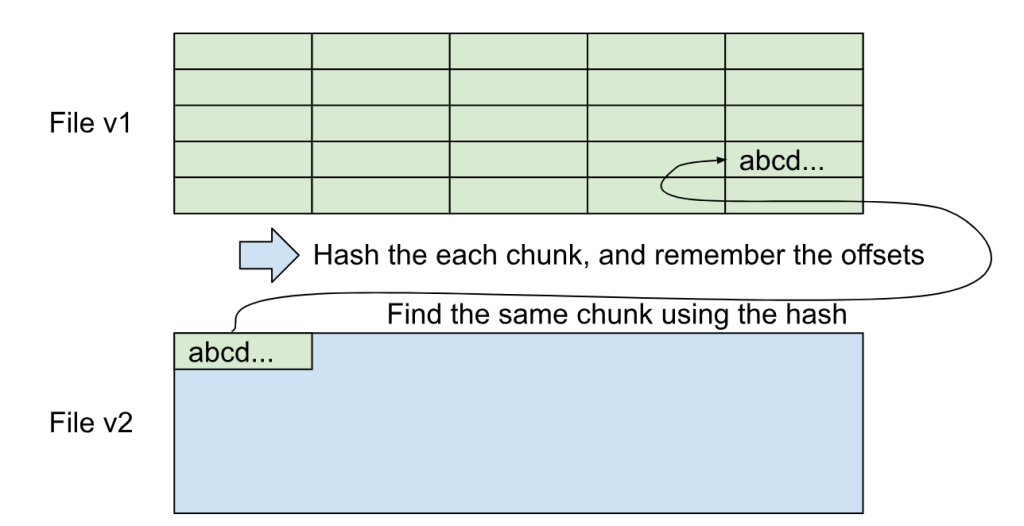
This algorithm is similar to the Rabin-Karp algorithm, but the hash is used for finding a common sequence. In Git, instead of “diff”, we call this copy/write command sequence as “delta”.
You can find the file v1’s indexing code in Git’s create_delta_index (https://github.com/git/git/blob/aa9166bcc0ba654fc21f198a30647ec087f733ed/diff-delta.c#L133), file v2 compression code in create_delta (https://github.com/git/git/blob/aa9166bcc0ba654fc21f198a30647ec087f733ed/diff-delta.c#L318), and the file v2 rebuilding code in patch_delta (https://github.com/git/git/blob/aa9166bcc0ba654fc21f198a30647ec087f733ed/patch-delta.c#L15).
Compressing more than one file
With the rolling hash method, we have delta = create_delta(file1, file2) and file2 = apply_delta(file1, delta). Now the question is how can we find such file1 and file2 pairs that compress well.
If we have unlimited compute resources, we can try all pairs in the repository, but we don’t. We need to use heuristics here. As we saw earlier, the delta only contains two kinds of commands: copy and write, and in order to minimize the delta, it’s better to have more copy commands instead of using write commands. Hence, finding similar files should result in better compression.
Intuitively, we can think that src/MyClass.java is similar to its past versions than other files. Git is using such heuristics to find the file1 and file2 pairs. This is explained in Git’s pack-heuristics documentation (https://git-scm.com/docs/pack-heuristics). These are the highlights of these heuristics:
- Same-name files are similar
- Files grow over time
- Latest versions are more accessed than older versions
- Keep the deltas shallow
Same-name files are similar
This looks obvious, but the same file’s v1 and v2 are very similar and well-compressed. Git does not only that but also it tries to find the same name files in a different directory.
When a file is moved to a different directory and the file name is the same, this allows Git to compress the files even before and after the file move. Also, if you need to put a configuration file for every directory, such as the BUILD file in Bazel, those files might have a similarity.
Files grow over time
In general, file and repository sizes get larger as the development continues. You might be proud of deleting more lines than adding, but the general tendency is that the software gets more features and gets more lines.
This insight gives us an interesting approach. It’s better to take a delta from the new version to the old version instead of the other way around. Since we as software engineers modify the file v1 and create a new version, we feel like the file v2 is built on top of the file v1. This is true with the diff output. If you run git diff, it shows how to create v2 from v1.
However, remember that the delta compression only has copy and write commands. Adding something to the base file needs more cost than removing something. Removing some data from a file is just a matter of not copying that portion.
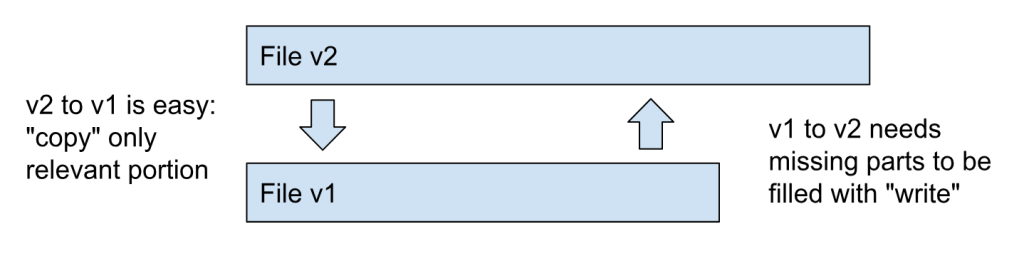
If files grow over time, then it’s better to create a delta from the latest version to old versions for better compression. This is a good bookkeeping task. As you write more code, you will make forward deltas (v1 to v2 deltas), and by running re-deltification, you can make them reverse deltas (v2 to v1 deltas) that provide better compression.
The latest versions are accessed more frequently than older versions
With delta compression, you have one full copy and one delta. In order to read the deltified version, you need to apply the delta to the full copy version. This means that accessing the deltified files needs some computational cost.
Having this in mind, when we get to choose which file to be the full copy, it’s better to choose the recent files than older files. This is because recent versions tend to be accessed more frequently than older versions. When cloning a repository, when creating a new topic branch, and when cutting a new release, we check out the recent version.
This is in line with the previous file size growth insight. Recent files tend to have a larger file size, so keeping the latest version as the full copy and deltifing the old versions makes sense from both aspects.
Keep the deltas shallow
The compression can be chained. For example, you can keep the file v5 and delta-compress the v4, then you can delta-compress v3 against v4, v2 against v3, and so on. If you do this, in order to read the file v1, you need to delta-uncompress v4, v3, v2, and v1. This needs unnecessary cost. Instead, you can delta-compress v1 through v4 against v5, and keep the delta chain shallow.
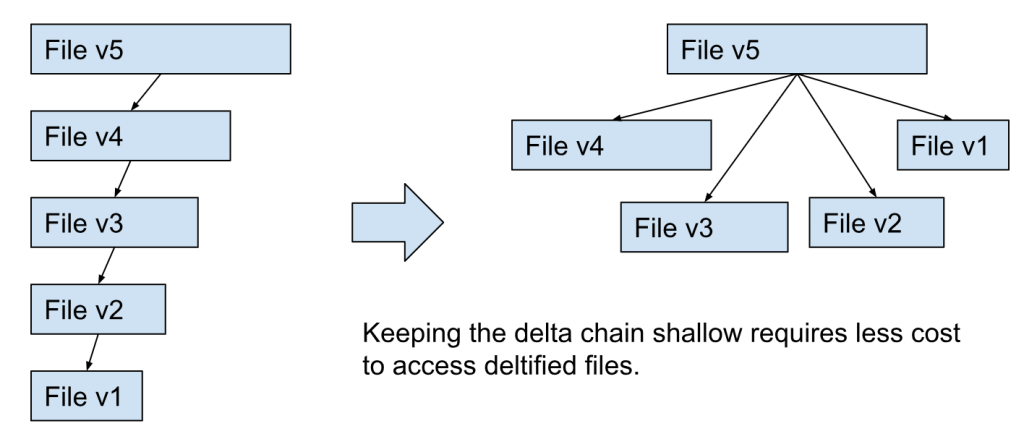
This way, you only need to delta-uncompress once to access v1.
Summary
In the article, we saw how Git compresses files using a rolling hash and the heuristics it uses to pick files to compress. Both of them come with great insights. The rolling hash has more applications such as documentation similarities.
The file recency and locality insights can be applicable to other caching systems. While Git’s file compression is a subtle topic and invisible to users, it is interesting to dive into.
Aviator: Automate your cumbersome processes
Aviator automates tedious developer workflows by managing git Pull Requests (PRs) and continuous integration test (CI) runs to help your team avoid broken builds, streamline cumbersome merge processes, manage cross-PR dependencies, and handle flaky tests while maintaining their security compliance.
There are 4 key components to Aviator:
- MergeQueue – an automated queue that manages the merging workflow for your GitHub repository to help protect important branches from broken builds. The Aviator bot uses GitHub Labels to identify Pull Requests (PRs) that are ready to be merged, validates CI checks, processes semantic conflicts, and merges the PRs automatically.
- ChangeSets – workflows to synchronize validating and merging multiple PRs within the same repository or multiple repositories. Useful when your team often sees groups of related PRs that need to be merged together, or otherwise treated as a single broader unit of change.
- TestDeck – a tool to automatically detect, take action on, and process results from flaky tests in your CI infrastructure.
- Stacked PRs CLI – a command line tool that helps developers manage cross-PR dependencies. This tool also automates syncing and merging of stacked PRs. Useful when your team wants to promote a culture of smaller, incremental PRs instead of large changes, or when your workflows involve keeping multiple, dependent PRs in sync.