
Impact of Flaky Tests in Merge Queue
Flaky tests, which fail unpredictably without changes in code or environment, can cause significant delays in development. They disrupt merge queues by blocking valid pull requests, leading to resets, wasted resources, and frustration among developers. Merge queues are designed to streamline the integration process, but flaky tests undermine their efficiency. Tools like Aviator MergeQueue help manage these challenges with features such as parallel testing and early validation. By addressing flaky tests and stabilizing testing environments, teams can ensure smoother workflows and more reliable CI/CD pipelines.

Flaky tests are a challenge many developers and QA teams encounter during software development. These are tests that occasionally fail despite no changes to the underlying code, producing inconsistent results across different executions. This unpredictability can disrupt workflows, erode trust in automated testing, and slow down development cycles.
In this blog, we will observe and understand how these flaky test cases can arise in a testing module and how you can steer clear of them when operating on a repository’s merge queue.
First of all, let’s understand what a merge queue is.
What are Merge Queues
Merge queues are automated systems designed to manage and sequence pull requests (PRs) effectively before integrating them into the main branch. By organizing and processing PRs in a controlled manner, merge queues can ensure that the changes are thoroughly tested, conflicts are resolved, and only stable, verified code is merged.
When Merge Queue is introduced into your Continous integration (CI/CD) workflows, it can play a critical role in bringing order to your deployment by ensuring that you experience:
- Streamlining Collaboration: They help coordinate multiple developers working on the same codebase, especially in busy repositories with numerous active pull requests.
- Maintaining Stability: Merge queues run automated checks, such as unit tests, integration tests, and linting, to catch issues early.
- Reducing Integration Failures: Sequencing merges and testing changes in isolation or combinations prevent broken code from reaching the main branch.
- Improving Developer Productivity: Teams spend less time dealing with manual merges, rebases, or debugging post-merge failures.
For more information on what CI/CD workflows are and how they foundationally strengthen your deployments, read this blog by Aviator.
Coming back, here are some scenarios where Merge queues are most helpful in avoiding headaches:
- Large Number of PRs:
- For high-traffic repositories like Kubernetes, React, and Go, which handle hundreds of daily pull requests, merge queues help process PRs systematically by running tests and resolving conflicts before merging. This reduces the maintainers’ workload, allowing them to focus on integrating stable code.
- Similarly, merge queues are essential in large organizations like Google or Microsoft, where multiple teams contribute to shared repositories. They ensure the orderly integration of simultaneous changes, reduce conflicts, and maintain repository stability across departments.
- Conflict Prevention:
- Merge queues help resolve conflicts in cases like overlapping file changes. For example, suppose two developers modify the same file or logic. In that case, the queue tests each PR sequentially against the latest branch state, ensuring changes are rebased or adjusted to avoid runtime issues.
- They are also valuable for complex system integrations, such as in repositories managing distributed systems. In such cases, merge queues validate PRs against the current state of all microservices to prevent breaking interdependencies.
- Maintaining Consistency
- Merge queues can automate quality checks, such as enforcing linting rules in projects using tools like Python’s Black or ESLint. They ensure consistent formatting by rejecting PRs that fail these checks.
- In DevOps pipelines, merge queues validate PRs by running unit tests, integration tests, and performance benchmarks. For example, a cloud deployment tool repository like Terraform might require tests to verify infrastructure templates before merging changes.
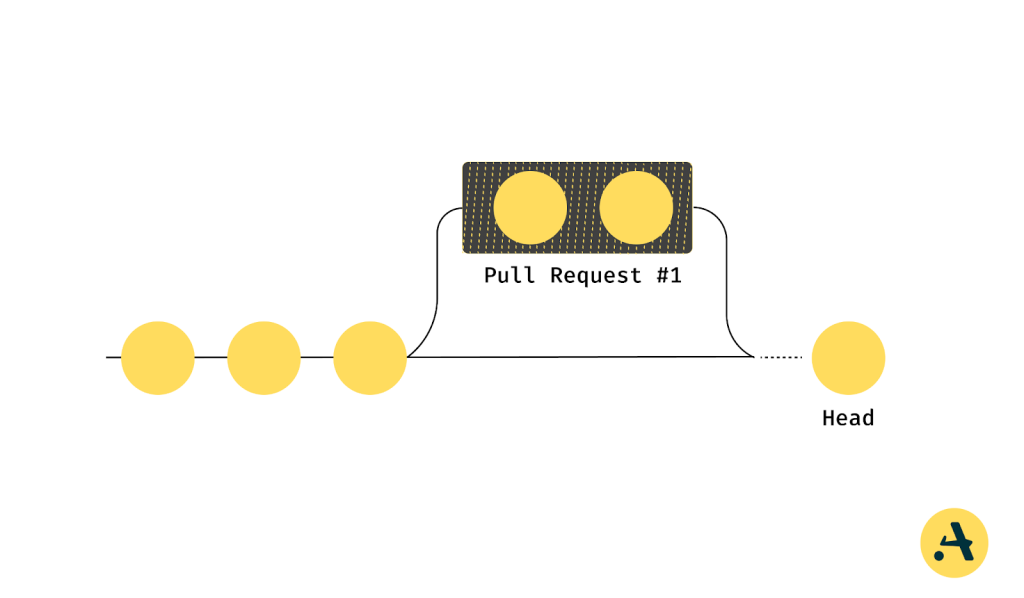
Merge Queues are mostly meant to be linear in fashion. Still, there are scenarios where multiple pull requests can safely proceed in parallel without affecting each other, such as when changes are isolated to different modules or components. This is handled by parallel mode in merge queues, which can significantly enhance efficiency. For instance, in a large-scale web application with separate teams working on distinct features like UI improvements and backend API updates, the parallel mode allows both PRs to be tested and merged simultaneously, speeding up the overall workflow. To learn more about how parallel mode works and its benefits, refer to Aviator’s documentation on merge queues.
To better understand how Merge Queues can bring good quality changes to your workflow and understand its foundation better, check out this blog by Aviator explaining Merge Queue.
Tools for Managing Merge Queues on GitHub
Several tools offer unique features that enhance integration workflows when integrating your repository with merge queues. Let’s take a look at some of the most widely used ones:
- GitHub’s Native Merge Queue
- GitHub offers a native merge queue that automates the process of merging pull requests sequentially, ensuring a streamlined and organized integration process.
- It integrates seamlessly with GitHub Actions, enabling CI/CD pipelines to run tests and other checks on each PR before it’s merged, ensuring that only stable and passing code reaches the main branch.
- Additionally, the system automatically prioritizes PRs based on their readiness, such as the successful completion of tests.
- Aviator MergeQueue
Aviator MergeQueue offers advanced features for a merge queue when compared to GitHub’s native Merge Queue. Aviator MergeQueue significantly enhances the management and integration of pull requests in busy repositories.
- One of its standout capabilities is support for parallel builds, enabling multiple PRs to be tested and merged simultaneously, significantly speeding up the workflow and reducing bottlenecks.
- It also supports complex workflows by handling dependencies between PRs, ensuring that changes are merged correctly, which is particularly useful in projects with interdependent components or services.
- Additionally, Aviator MergeQueue allows prioritizing PRs based on configurable criteria, such as test results, the severity of changes, or even team preferences, providing greater control over the merge process.
- Its deep integration with GitHub Actions enhances CI/CD automation by triggering customized workflows for each PR in the queue, ensuring that all checks are performed automatically.
Challenges with GitHub’s merge queue
GitHub’s native merge queue offers basic automation for sequential pull requests, but its limitations can hinder more advanced workflows. One significant drawback is the lack of support for parallel builds, which means PRs are processed one at a time. This can slow down integration, especially in large or high-traffic repositories with multiple PRs requiring attention. The merge queue must also be better suited for handling complex dependencies between PRs, which is problematic for projects with interdependent changes across different modules or services. This inflexibility can lead to integration challenges and delays.
Another area for improvement is its inability to address flaky tests effectively. Flaky tests produce inconsistent results and are standard in fast-moving development environments. With built-in support to manage these, development pipelines can become reliable. Moreover, the native merge queue offers limited features for managing parallelism, making it less suitable for repositories requiring robust parallel testing or simultaneous PR validations.
For teams dealing with complex workflows or dependency-heavy projects, alternative tools like Aviator MergeQueue or Mergify provide advanced capabilities such as better dependency handling, parallel processing, and flaky test management, offering a more scalable approach to CI/CD workflows.
Now that we are clear on the functionality of Merge Queue Let’s see how you can set up a merge Queue for your GitHub repository.
How to Setup Aviator’s Merge Queue in GitHub
Let’s see how to implement a Merge Queue on your GitHub repositories.
For this blog, we will implement and use Aviator MergeQueue over your GitHub’s native merge queue, as it has the added benefit of managing your PRs better.
First of all, you will need to create a new account on Aviator. Aviator’s minimal onboarding process gets you on your task immediately.
For Aviator to access your repositories, you need to connect your GitHub account to Aviator and authorize it to access at least one of your repositories.
Then, create a remote repository on github. You can name it anything and then add some commits to it. You can follow this Aviator blog to learn how to start with MergeQueue.
What is a Flaky Test
As we discussed above, a flaky test passes or fails inconsistently, often without any changes to the underlying code. Flaky tests can create significant challenges in the development process, introducing uncertainty into the CI/CD pipeline. For a deeper understanding of flaky tests, check out our blog.
Common causes of flaky tests include timing issues, where tests are sensitive to execution order or timing conditions, and race conditions, which occur when tests depend on the timing of multiple parallel processes. Flaky tests can also arise from reliance on external systems, such as APIs or databases, that might be unstable or not fully synchronized.
The impact of flaky tests on development is far-reaching. They waste time as developers are forced to repeatedly investigate and address test failures that may not be related to the actual code changes. This inconsistency reduces confidence in the CI pipeline, as developers may question the test results’ reliability. This leads to delayed merges, as PRs get stuck in the queue due to failing tests, even if the code itself is sound. Over time, flaky tests can significantly slow down development cycles, leading to frustration and decreased productivity.
Example Scenarios
Let’s look at some example scenarios where flaky tests can arise:
Critical Bugs Slipping Through
In a high-traffic repository like Kubernetes, a flaky test intermittently passes despite underlying issues in the code. A PR introducing a subtle bug in pod scheduling bypasses the merge queue due to the test’s false success. The bug isn’t caught until it causes downtime in production, forcing an emergency patch and shaking user confidence.
Erosion of Trust in CI Pipelines
In a repository like React, developers need help with frequent flaky test failures during validation. Over time, team members begin to doubt the reliability of the CI pipeline, choosing to skip automated validation or manually bypass failing tests. This manual intervention increases the risk of merging untested code and consumes valuable engineering hours that could be better spent on feature development.
Merge Queue Delays in Dependency-Heavy Projects
For a repository managing a distributed system, such as Airflow, a flaky test related to DAG scheduling needs to be revised sporadically. This resets the merge queue for every affected PR, delaying updates to core modules. The cascading delays slow down the integration of other critical components like new operators or plugins, impacting the entire development cycle.
Refer to this blog to further understand why flaky tests occur and how to mitigate them.
Different Levels of Flaky Tests
Flaky test cases can occur at various levels of frequency, each with its own impact on the development process. These variabilities in flaky tests can significantly impact the efficiency of the merge queue.
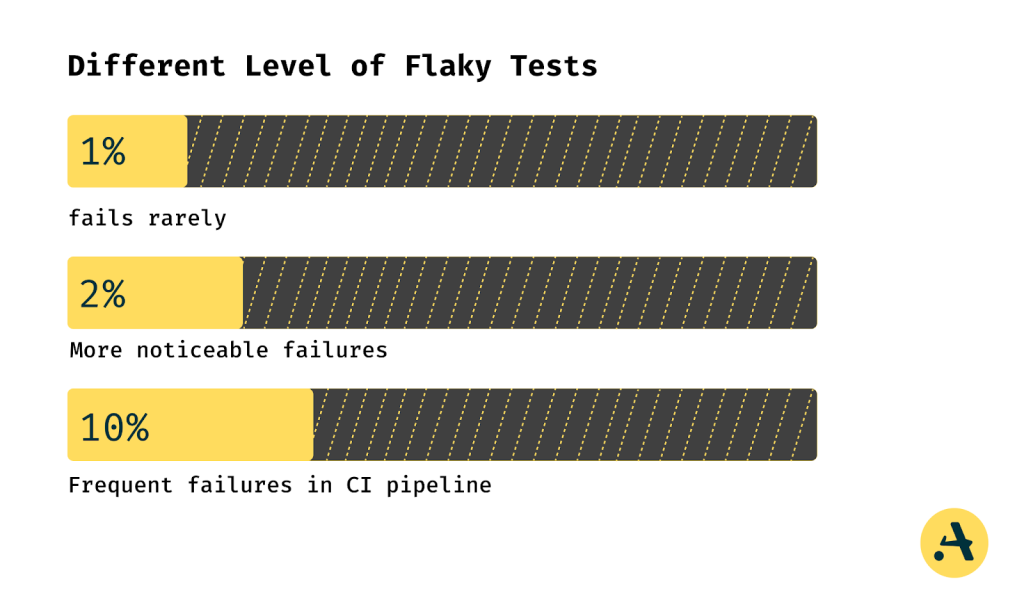
1% Flaky Tests
These are tests that fail rarely but still disrupt workflows when they do. For example, a test might fail due to a slight network delay or timing issue, temporarily causing the merge queue to stall. While it only happens sometimes, when it does, it can still lead to wasted time and frustration for developers who need to investigate and address the failures manually. The impact on merge queue efficiency is limited but still noticeable, especially for teams working with high-traffic repositories or under tight deadlines.
2% Flaky Tests
At this level, flaky tests cause more noticeable slowdowns and retries in the CI/CD pipeline at this level. These tests may fail a few times daily, leading to frequent interruptions in the merge queue. Developers will spend more time addressing flaky test failures, making the merge process less predictable and more time-consuming. The cumulative effect of having even just a few flaky tests at this rate can be significant, especially for teams with many PRs waiting in the merge queue or for larger and more complex repositories.
10% Flaky Tests
Flaky tests at this level fail so frequently that they cause constant CI/CD process disruptions. Every new pull request is affected, and the merge queue becomes almost unusable, with repeated resets and retries. The CI/CD pipeline grinds to a halt, and the workflow slows down to a crawl. Developers will be forced to spend considerable time dealing with flaky test issues, investigating and potentially fixing problems that may not be related to actual changes. This level of flaky tests can devastate merge queue efficiency, leading to prolonged integration times, lost productivity, and frustration for the entire development team.
Cumulative Effect of Flaky Tests on Merge Queue Efficiency
The cumulative effect of flaky tests at any of these levels can be substantial. Even a small percentage of flaky tests can slow down the integration process, increase the time spent on retries, and lead to wasted development time. As flaky tests increase in frequency (up to 10% or more), they seriously disrupt the merge queue’s effectiveness, causing delays, reduced confidence in the CI/CD pipeline, and a significant slowdown in the development workflow. For teams with a high volume of PRs or complex repositories, flakiness in test automation can become a significant bottleneck that needs to be addressed to maintain efficiency and reliability in the CI/CD pipeline.
How Flaky Tests Affect Merge Queue
Until now, you might have a pretty good idea of how unpredictably a flaky test is on a merge queue. These tests, which pass or fail randomly due to issues like race conditions, timing dependencies, or unreliable external systems, undermine the efficiency of the queue and slow down merges.
The Chain Reaction of Flaky Test Failures
When a flaky test fails during the validation of a pull request (PR), it blocks progress for the affected PR and all others waiting in the queue. For example:
- PR Validation Fails: A test in a critical module intermittently fails despite no issues in the code.
- Queue Halt: The failed PR must be debugged and re-run, blocking subsequent PRs in the merge queue.
- Delay Amplification: As each failure causes delays, other PRs accumulate in the queue, leading to a bottleneck.
Developer Overhead
Flaky test failures add unnecessary overhead for developers:
- Time-Consuming Debugging: Teams spend hours investigating failures, only to find no actual defects in the code.
- Re-runs and Resource Wastage: Developers must re-run pipelines multiple times, consuming CI/CD resources and increasing operational costs.
- Erosion of Confidence: The unpredictability of flaky tests leads to frustration, with developers losing trust in automated pipelines. This can result in workarounds like manually bypassing tests, increasing the risk of introducing bugs.
Example Scenario
Scenario 1: Race Condition in Asynchronous Code
A flaky test might intermittently fail due to a race condition when testing asynchronous code, causing random failures in the merge queue.

Impact on Merge Queue:
If multiple PRs depend on this test, a failure could block the entire queue, requiring reruns and delaying merges.
Scenario 2: Network Dependency
A test that relies on an external API or service might fail due to temporary network issues or API unavailability, even when the code is correct.

Impact on Merge Queue:
Intermittent failures can cause false negatives, requiring manual intervention or retries in the CI pipeline.
Scenario 3: Environment Specific Dependency
A test might pass locally but fail in the CI environment due to differences in environment configurations, such as time zones, locales, or system resources.

Impact on Merge Queue:
Such failures might lead developers to suspect the CI environment or the test itself, reducing trust in automated pipelines.
Scenario 4: Resource Contention
Tests that rely on shared system resources (e.g., files, ports) might fail intermittently when run concurrently in the CI pipeline.
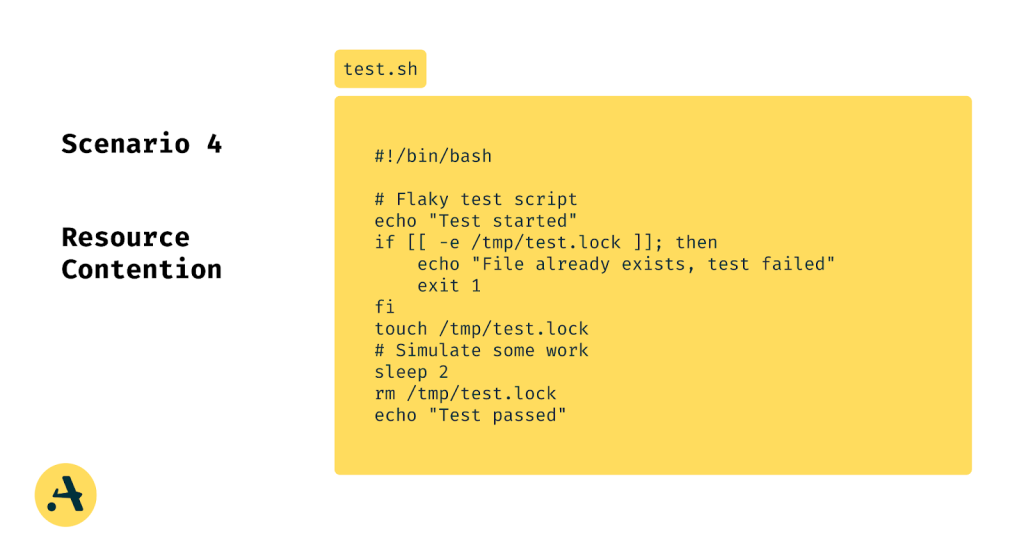
Impact on Merge Queue:
Concurrency issues might cause false negatives when multiple tests run simultaneously, blocking other PRs.
Scenario 5: Non-Deterministic Behavior
Tests relying on random data or processes with non-deterministic outputs might fail unpredictably.
Impact on Merge Queue:
This unpredictability leads to unnecessary debugging efforts and pipeline reruns, wasting time and resources.
Breaking the Cycle
To mitigate these issues, teams can:
- Quarantine flaky tests to prevent them from disrupting the merge queue.
- Use optimistic validation to prioritize reliable tests.
- Leverage tools like Aviator MergeQueue to manage flaky tests effectively and maintain queue efficiency.
Addressing flaky tests is essential to ensuring smooth, predictable merges and preserving developer productivity.
How Flaky Tests Cause Merge Queue Resets
When a flaky test fails during validation, it causes the entire PR to be marked as failed, even though the code itself may be error-free. This resets the PR in the queue and triggers a ripple effect on other queued changes.
Cascading Effects of Flaky Tests
The impact of flaky tests isn’t limited to a single PR. Here’s how they create a cascade of inefficiencies:
Queue Disruptions: A flaky test failure causes the affected PR to drop out of the queue, requiring a revalidation cycle. This delay impacts all subsequent PRs, as the queue often operates sequentially or in carefully managed batches.
Re-runs and Resource Wastage: Each revalidation forces the CI/CD system to rerun the entire suite of tests for the PR, consuming computational resources unnecessarily. For high-traffic repositories, this can lead to significant delays and inflated CI/CD costs.
Blocked Development Cycles: Other PRs that depend on the queue’s progress are held up, slowing down the development and release pipeline. Teams may face delays in deploying new features or fixing critical bugs due to these queue resets.
Developer Frustration
Flaky tests erode CI/CD pipeline trust, leading to widespread developer frustration. Engineers must frequently debug failed tests, only to discover that the issue wasn’t with their code but with an unreliable test. This diverts focus from meaningful development work and creates friction within teams. Over time, teams may resort to bypassing the merge queue entirely, potentially compromising code quality and introducing risks into the main branch.
For a deeper dive into managing flaky tests effectively and preventing merge queue disruptions, refer to Aviator’s blog on Managing Flaky Tests. This resource explores practical solutions like isolating flaky tests, implementing optimistic validations, and reducing their impact on CI/CD workflows.
How to Prevent Flaky Tests
Till now, you have understood how Flaky tests can seriously affect your CI/CD workflow, and preventing flaky tests is crucial for maintaining a stable and efficient CI/CD pipeline.
You can use these following strategies mentioned below to reduce flaky tests in your workflow:
Use Mock Data and Isolate Tests from External Dependencies
To avoid flaky tests caused by external systems such as APIs and database endpoints, mock data and isolate tests from these dependencies should be used. This ensures network delays, API unavailability, or fluctuating database states do not impact tests.
If you’re testing an API call to an external service, use a mocking library like WireMock or Nock to simulate the API’s responses. This removes the variability of external systems and ensures consistent test results.
Improve Test Environment Stability with Containerization Tools like Docker
Using Docker or other containerization tools can help ensure that tests run in a consistent environment. By containerizing your application and tests, you reduce discrepancies between different development and test environments, making tests more reliable.
Set up a Docker container that mirrors your production environment, ensuring that tests are run in the same configuration each time. This can eliminate issues where tests pass on one machine but fail on another due to environmental differences.
Regularly Review and Refactor Tests to Remove Non-Deterministic Behavior
Periodic review and refactoring of tests can help identify and fix non-deterministic behavior, such as dependencies on time, random values, or order of execution.
Replace tests that depend on setTimeout or setInterval with deterministic alternatives, such as using libraries like Sinon.js to mock timing functions.
Implement Retries Selectively with Logging to Identify Root Causes
While retries can help mitigate flaky tests, they should be used sparingly and with careful logging to help identify the root cause of the failures. Implementing retries without tracking can mask the underlying issues.
In CI tools like GitHub Actions, the retry action with a logging mechanism captures additional details when a test fails intermittently. This ensures you only retry tests when necessary and helps pinpoint recurring failures.
Use Aviator’s Optimistic Validation Approach to Prevent Merge Queue Resets
Aviator’s optimistic validation allows PRs to be validated earlier in the merge queue before they encounter flaky tests, reducing the disruptions caused by test failures. This method ensures that the PRs in the queue are more likely to succeed and move forward without unnecessary resets.
By configuring Aviator MergeQueue to validate tests in parallel while skipping non-deterministic tests, the queue can continue processing unaffected PRs, speeding up the overall process and reducing the time spent resolving flaky tests.
How Aviator Solves Queue Reset Issues with Optimistic Validation
Aviator’s Optimistic Validation feature helps address the challenge of flaky tests by enabling quicker validations earlier in the queue, reducing unnecessary delays without impacting the workflow of other PRs. This is achieved by using two main configuration settings: use_optimistic_validation and optimistic_validation_failure_depth.
The use_optimistic_validation flag allows tests to be validated before previous tests are fully completed, aiming to confirm that the PR is likely valid without waiting for the full queue to clear. This speeds up the merge process by catching successful tests earlier. On the other hand, the optimistic_validation_failure_depth is particularly important for flaky tests. It defines how deep Aviator should check into the validation process before concluding that a test failure is likely caused by instability, not an actual issue with the code. This way, Aviator can bypass inevitable failures more likely to be false positives, preventing unnecessary disruptions in the queue.
By isolating flaky tests and applying targeted retries, this feature speeds up the workflow and minimizes disruptions for teams working with large codebases or frequent updates. This makes the process more efficient by ensuring that tests that frequently fail due to instability are handled appropriately.
Best Practices When Handling Tests in Merge Queues
Undoubtedly, you won’t find any edge cases or conflicts when working with merge queues. However, you can incorporate some good practices in your workflow to reduce these issues:
- Set Up Automated Flaky Test Detection and Quarantine Affected Tests
It’s important to set up automated detection for flaky tests, which are tests that intermittently fail without any changes to the code. These tests can cause delays in the merge process and lead to unreliable results. Use tools to automatically identify and quarantine flaky tests so they don’t block merges. This helps ensure that only reliable tests contribute to the decision-making process for merging pull requests. - Use Tools Like Aviator MergeQueue to Ensure Only Reliable Tests Block Merges
Merge queues should be configured to block merges only when reliable, passing tests fail. Tools like Aviator MergeQueue offer advanced features that can help filter out flaky tests, ensuring that only consistent and stable tests affect the merge process. This reduces the chance of unnecessary merge delays due to unreliable tests. - Conduct Periodic Test Audits to Identify and Fix Unreliable Tests
Regularly audit your test suite to identify any unreliable or flaky tests. A thorough review of the tests can help pinpoint issues with the test environment, dependencies, or the tests themselves. By fixing unreliable tests, you improve the overall quality of your testing process and prevent them from hindering the merge queue. - Enable Selective Testing to Rerun Only Affected Areas of the Codebase
Instead of rerunning the entire test suite for every change, enable selective testing to focus on the areas of the codebase that have been directly affected by the pull request. This reduces the overall execution time of your test suite and allows for quicker feedback, helping to maintain a fast and efficient merge process. Limiting test runs to the changed portions of the code will enable you to speed up the validation process without compromising test coverage.
Conclusion
This blog explored the challenges of flaky tests and their disruptive impact on CI/CD pipelines and merge queues. We discussed how flaky tests cause workflow delays, merge queue resets, and developer frustration, highlighting their root causes like timing issues and external dependencies. Merge queues, incredibly advanced tools like Aviator MergeQueue, were shown to be essential in maintaining stability by managing flaky tests through features like parallel builds and optimistic validation.
We emphasized isolating unreliable tests, containerizing environments, and implementing selective testing to mitigate flaky tests. By adopting these practices and leveraging tools like Aviator, teams can reduce disruptions, improve merge efficiency, and focus on delivering high-quality software. Addressing flaky tests ensures smoother workflows and more reliable CI/CD pipelines.
FAQs
What is the role of a merge queue in CI/CD pipelines?
The merge queue will ensure the pull request’s changes pass all required status checks when applied to the latest version of the target branch and any pull requests already in the queue. A merge queue may use GitHub Actions or your own CI provider to run required checks on pull requests in the merge queue.
How do flaky tests impact development?
Flaky tests slow down the development process and increase costs. If a test fails randomly, it may require multiple reruns, manual verification, or debugging to determine the root cause. This can delay the delivery of features, fixes, or releases and consume valuable resources and budget.
Can Aviator MergeQueue handle flaky tests?
Aviator automates tedious developer workflows by managing git Pull Requests (PRs) and continuous integration test (CI) runs to help your team avoid broken builds, streamline cumbersome merge processes, manage cross-PR dependencies, and handle flaky tests while maintaining their security compliance.
What tools can detect flaky tests?
Various frameworks and tools like BrowserStack Test Observability, BuildKite, and FlakyBot can help detect and diagnose flaky tests automatically.








