
Merge Queues for Large Monorepos
Merge queues in monorepo can be challenging to maintain. Learn how to create that stability while maintaining high throughput in a monorepo.

Monorepo is a practice to maintain large unified code repositories. It doesn’t necessarily mean using a single repository; it refers to large repositories shared by multiple teams. Sometimes an organization can have multiple monorepos, one for each language. Monorepo makes sharing and reusing code easier, but it also brings challenges—like managing dependencies, avoiding conflicts, and handling a lot of pull requests.
Merge queues help by organizing pull requests into a system that tests each one before merging, making sure the main branch stays stable. They save time by automating updates and testing, so developers don’t have to constantly recheck their changes. Tools like Aviator make this process smoother, especially for large teams, by focusing only on what needs testing and keeping things moving efficiently.
This blog will guide you through:
- When to Use Merge Queues for Monorepos?
- Challenges of Scaling Merge Queues
- How Development Looks Without a Merge Queue
- A practical look at how affected targets feature can help improve the queues.
- How do we manage flaky tests that can disrupt queues?
- Batching in parallel mode to optimize throughput.
When to Use Merge Queues for Monorepos?
Using merge queues becomes really important in monorepos when you’re dealing with a large number of pull requests coming in all the time. Since everything in a monorepo is connected, a change in one part of the code can easily affect another part, causing problems like dependency issues or conflicts. On top of that, if your builds and tests take a long time to run, it slows everything down even more because you have to keep re-testing every time something changes.
That’s where parallel mode in merge queues can be a big help. It lets you handle multiple pull requests at once, speeding things up and cutting down on wait times. But it’s not all straightforward—when you’re testing and merging several changes at the same time, you have to be extra careful about avoiding conflicts and keeping everything working smoothly. We’ll dig into how this works and some of the challenges it brings next.
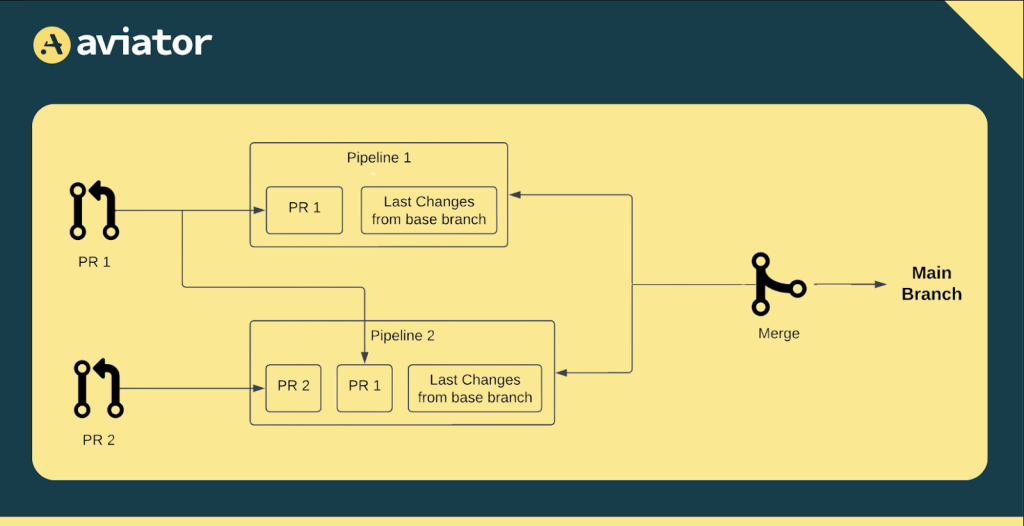
Using merge queues in monorepos is a great way to keep pull requests (PRs) organized and maintain stability in the main branch. However, scaling them effectively for large monorepos comes with its own set of challenges. Let’s take a look at some of the common challenges that come with scaling merge queues in large monorepos.
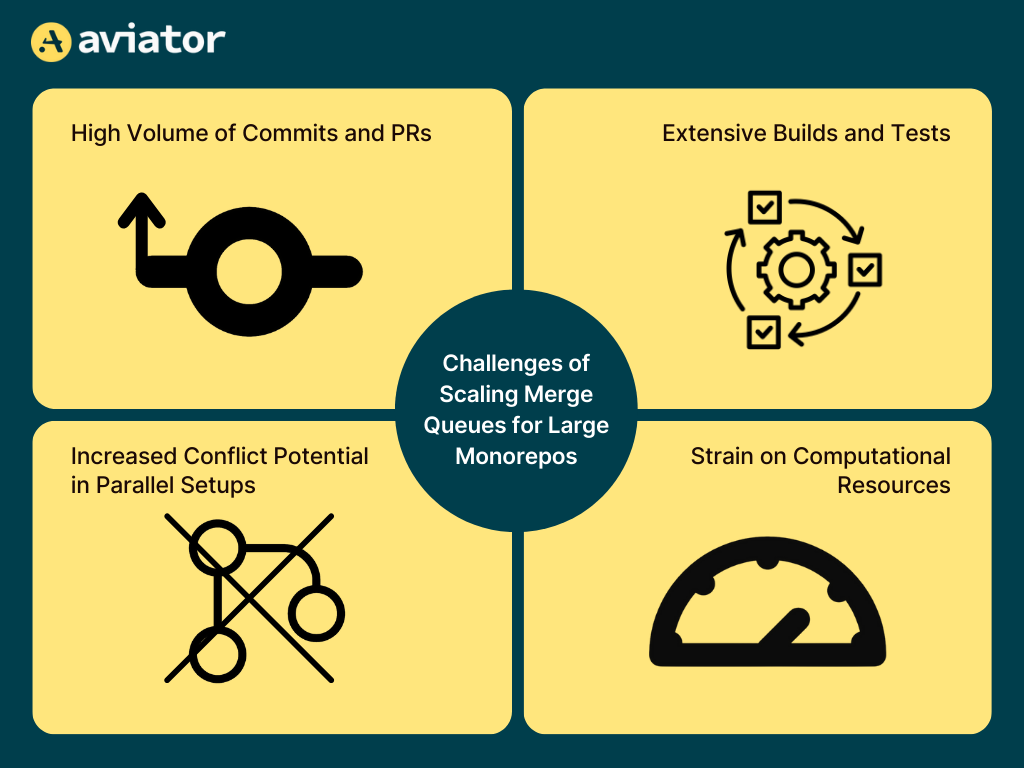
Challenges of Scaling Merge Queues for Large Monorepos
Scaling merge queues for large monorepos can be tough. The number of pull requests (PRs) and commits can pile up, making the queue move slowly. On top of that, monorepos often have large builds and test processes, meaning even small changes can take a lot of time to test. This slows down how fast changes can be merged.
To speed things up, teams sometimes test and merge multiple PRs at the same time, called parallel processing. While this helps save time, it can create issues when two PRs make changes to the same part of the code. For example, if two teams edit the same core file, merging one can cause the other to fail, leading to more delays and rework.
Another problem is the demand on resources. Running multiple builds and tests at once requires a lot of computing power, which can be expensive. Big companies with complex monorepos, like Netflix or Airbnb, often spend a lot on cloud services to handle this. It’s not always easy to find the right balance between speed and keeping costs under control.
The goal is to keep things running smoothly while avoiding wasted time or effort. Teams need good strategies to handle test failures, avoid conflicts, and use resources wisely. With careful planning, merge queues can work well even for very large monorepos.
Before diving into the specifics of merge queue, it’s important to understand how development looks without a merge queue.
How Does Development Look Without a Merge Queue?
Without a merge queue, managing pull requests (PRs) in a large monorepo can become frustrating and slow. Imagine many developers working on related parts of the code. Whenever one PR gets merged, the rest need to be retested to make sure they still work with the latest changes. This repeated testing eats up time and keeps PRs stuck in the process longer than necessary.
Conflicts between PRs are also common. For example, if two changes affect the same part of the code, merging one can cause the other to fail. Developers then need to fix these issues and rerun tests, which slows everyone down.
This constant cycle of fixing and retesting can feel like progress is dragging. It takes valuable time away from developing new features and leaves teams frustrated. A merge queue solves these issues by organizing PRs, testing them in order, and reducing conflicts so work can move forward more smoothly.
Here’s a quick comparison between the two ways of development – with and without a merge queue:
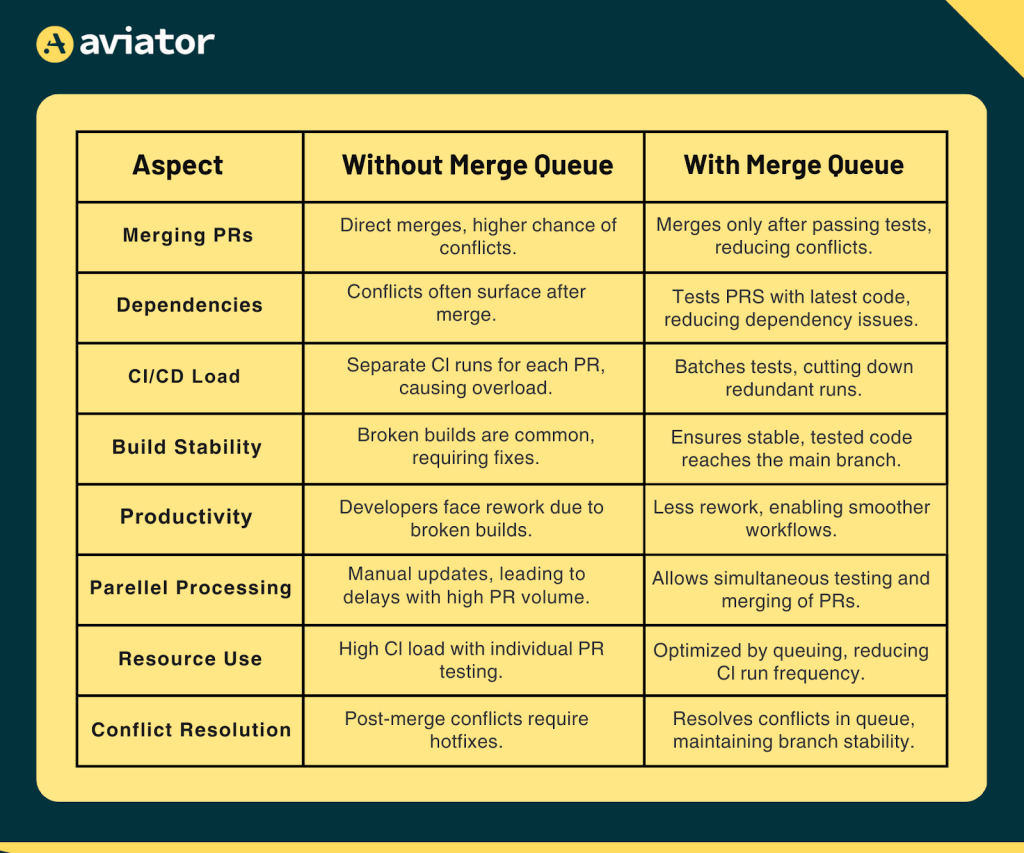
To avoid the problems mentioned earlier, tools like Aviator’s merge queue offer a more efficient way to handle pull requests and ensure smoother development cycles.
Using Affected Targets to Improve Merge Queues in Aviator
Using affected targets is an efficient way to improve merge queue performance, especially in large monorepos where different areas of code can be independent of each other. This strategy focuses on only testing the parts of the codebase directly impacted by a pull request (PR) rather than testing the entire repository each time, saving time and computing resources. Here’s how it works and why it’s effective:
In a monorepo, there are usually multiple services or modules, each serving a different purpose. Let’s say there’s a repository with two main modules: a frontend and a backend service. If a developer makes a PR that changes only the backend, testing the frontend is unnecessary. Aviator’s affected targets system identifies that the frontend is unaffected, so it skips testing the frontend for that PR. This is helpful for three reasons:
- Reduces Testing Time: Since Aviator is only running tests on what’s directly impacted by the code changes, CI time is cut significantly. For instance, in a large monorepo with a complex CI setup, a single CI run might take hours if every module has to be tested. By isolating just the affected parts, that same run could be reduced to minutes. This means PRs that only impact a specific part of the code won’t have to wait in line behind PRs that affect other areas.
- Prevents Bottlenecks in the Queue: Without affected targets, all PRs would be lumped into the same queue and tested one after the other, creating a bottleneck as developers wait for unrelated tests to finish. With affected targets, Aviator can create “mini-queues” based on code impact. For example, frontend PRs can run independently of backend PRs, meaning developers are less likely to be blocked by unrelated PRs.
- Improves Developer Efficiency and Morale: When developers know their PR won’t be held up by unrelated changes, they can be more productive. A developer working on a UI change won’t need to worry that backend changes might slow their PR’s progress and vice versa. This independent workflow reduces the frustration of waiting for changes that have no impact on a developer’s own work.
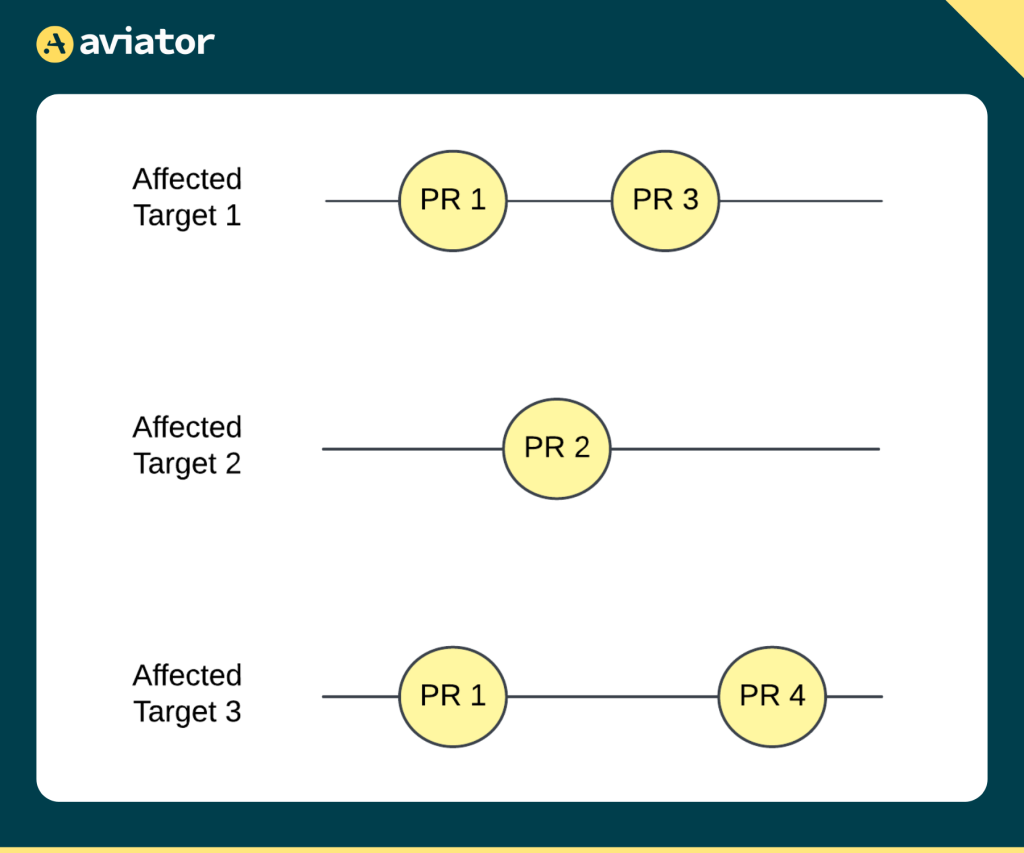
Using affected targets means that even in a large, shared codebase, teams can move quickly by focusing testing on only what’s changed. Aviator’s dynamic queueing based on affected targets keeps the process flexible, letting each PR run independently when there’s no overlap with others.
To further optimize the merge queue process, it’s important to consider how flaky tests can impact efficiency and cause delays.
Flaky Tests and Their Impact on Queues
Flaky tests are tests that fail unpredictably, often without any changes to the code. They’re a major headache in CI/CD pipelines because they make it hard to know if a failure is due to an actual issue or just random error. In a merge queue, especially when using parallel mode to process multiple pull requests (PRs) at once, flaky tests can disrupt the entire flow. Imagine a scenario where multiple PRs are queued and ready for testing: if even one flaky test fails, it can cause all the PRs in that batch to be re-tested, wasting time and resources.
Aviator has a solution to this with its optimistic validation feature. Instead of automatically removing a PR from the queue if a test fails, Aviator waits to see if other PRs in the same batch pass successfully. The idea is that if only one PR has a flaky failure while others pass, the test failure might not indicate a real issue, but rather a random glitch. So, Aviator keeps that PR in the queue instead of resetting the queue and running all the tests again.
For instance, say a developer’s PR is waiting in the queue with others, and a single test fails due to a temporary server error. With optimistic validation, Aviator doesn’t punish the developer by removing the PR; it simply allows the queue to move forward, assuming the failure is flaky unless other failures confirm it’s a real issue. This helps keep the workflow moving smoothly, avoids frustrating and repetitive test failures, and prevents the CI system from getting bogged down by unnecessary re-tests.
To further enhance the efficiency of merge queues, batching is a strategy that groups multiple PRs together to process them more effectively.
Batching as a Throughput Optimization Strategy
Batching is a technique that combines multiple pull requests (PRs) into a single CI run. Instead of testing each PR individually, batching groups several PRs together to be tested at once. This cuts down on the total number of CI runs, which is especially helpful when there’s a high volume of PRs. It makes the process faster by reducing the total workload, and it minimizes redundant testing for similar code sections across PRs.
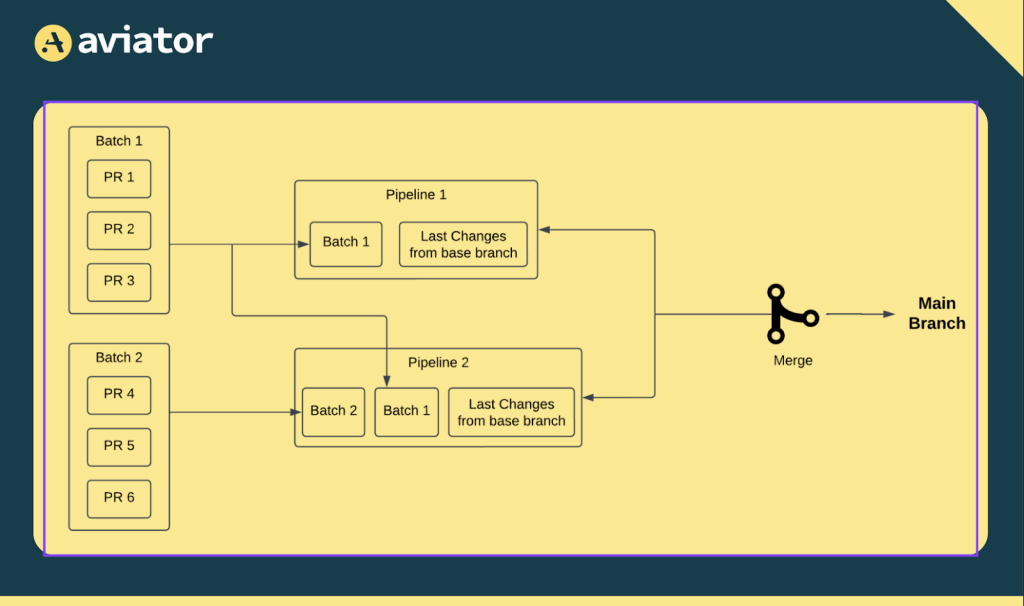
However, batching isn’t without its challenges. When a batch fails, it can be hard to pinpoint which PR caused the issue because all the changes are tested together. To address this, Aviator uses a method called bisection. Let’s say five PRs are batched together, and the batch fails. Instead of rerunning each PR individually (which would be slow), Aviator splits the batch into smaller groups—maybe testing two PRs together in one group and three in another. This process repeats until it narrows down the problematic PR.
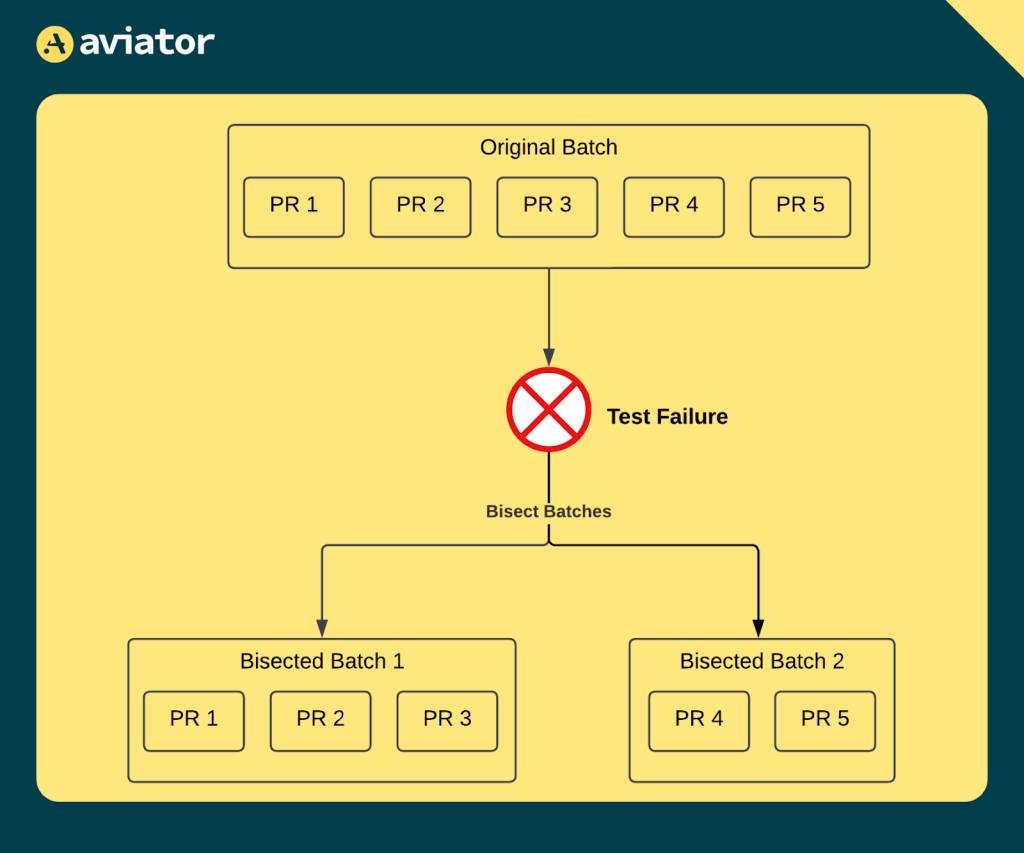
Imagine five PRs that each tweak a part of the UI. If one introduces a bug that causes the test to fail, Aviator’s bisection can quickly isolate which PR caused the issue. This way, Aviator can keep the queue moving efficiently without needing to stop and re-run every PR. Batching and bisection together keep CI pipelines lean and reduce the load on the system, allowing developers to get feedback faster and manage resources more effectively.
Conclusion
Scaling merge queues for large monorepos requires thoughtful strategies, from affected targets and batching to handling flaky tests. Aviator’s tools, designed with these challenges in mind, provide a robust solution to maintain queue efficiency and stability. By implementing these strategies, teams can ensure a smoother, faster CI/CD process in even the largest monorepos. Check out Aviator’s quick setup guide to get started with the merge queue for your monorepo.

Frequently Asked Questions
Q. How does the merge queue work on GitHub?
GitHub merge queue automatically organizes and merges pull requests (PRs) into a branch once all required checks pass. It ensures that PRs don’t conflict with others and that the branch remains stable by running tests in a simulated environment. This system is especially useful for busy branches with multiple active contributors.
Q. How to do a merge request in GitHub?
To initiate a merge (pull) request in GitHub, go to the target repository, select the branch with your changes, and create a PR from the Pull Requests tab. Once submitted, collaborators can review and approve the PR before merging it into the main branch.
Q. What does merge do in GitHub?
A merge in GitHub integrates changes from one branch into another, typically merging feature branches into the main branch. This combines code updates, resolving conflicts if needed, and unifying changes into a single branch.
Q. How do I bypass the merge queue in GitHub?
If permitted by branch protection rules, admins or authorized users can bypass the merge queue by selecting the “Merge without waiting for requirements to be met” option. This direct merge skips pending checks but may be restricted based on repository settings.








