Merge strategies to keep builds healthy at scale
This post features a distillation of various merge strategies that help teams scale and their associated developer-productivity trade offs.
How hard can merging really be? All you have to do is press this green button and your changes are merged.
Maybe. But let’s take a closer look anyway.
First, let’s think a little bit about the different repositories that teams use: Monorepos and polyrepos. A monorepo has the entire engineering team using a single repository whereas a polyrepo has every team within a company, potentially, using a separate repository.
Monorepo advantages:
- Typically, you have an easier time managing dependencies.
- You can easily identify vulnerabilities and fix them everywhere
- It’s easier to do refactoring, especially cross-project
- Standardization of tools as well as code sharing
- You can share the same libraries across different projects
Polyrepo advantages:
- Simpler CI/CD management. Everyone has their own different CIs, so there are fewer build failures.
- You’re independent, you have independent bid pipelines, and build failures typically are localized within the team
In this post, we will focus on monorepos and identifying the challenges a large team faces when working with one.

Is your current CI system enough?
Consider this: how often do your mainline builds fail, and is your current CI system enough? Let’s talk through it.
There are several reasons why your mainline builds may fail:
- Dependencies between different changes that are merging
- Implicit conflicts due to developers working on a similar code base
- Infrastructure issues (timeouts, etc.)
- Internal as well as third-party dependencies that can cause failures. Obviously, there are risk conditions in shared spaces that also cause flaky tests.
Stale dependencies and implicit conflicts
Given that we’re working a monorepo, let’s say there are two requests where they’re merging together or they’re based out at two different times from your main. Both have a passing CI, but eventually, when you go to those changes, the main line fails.
This could happen because both of them may be modifying the same pieces of code that aren’t compatible with each other. As your team grows, these issues become more and more common. Eventually, teams start setting up their own build police to make sure that if a build fails that there’s somebody responsible for fixing it.
There will be rollbacks, delayed releases, and chain reactions where people are basing off of filling branches, and then they’ll have to figure out how to actually resolve those issues.
And these failures increase exponentially as your team size grows. That’s why it becomes critical to make sure you can actually take care of it so that developer productivity is not significantly impacted.
You don’t want a situation where everyone is just waiting for the builds to become green. They cannot merge any changes because builds are always broken and you’re losing important developer hours.
So what’s the solution?
Merge automation
Let’s dive more into how merge automation works and how you can adopt it internally.
To give you a very simple example, consider a request we’ll call PR1. Instead of developers manually merging these changes, they typically inform the system that it’s ready. At this point, instead of merging changes itself, the system actually merges the latest main into this port request and then runs the CI.
The advantage here is you’re always validating the changes with the most recent main. If the CI passes, this PR will get merged. But what if there’s a PR2 that comes in while the CI’s running? It’s going to wait for PR1 to merge before it picks up the changes of the latest main and then process and run the same thing. So once PR2 passes, it’s going to merge the same way.
How much time does this take?
Let’s assume for the sake of argument that the CI time is about 30 minutes. If you’re merging in a small team you’re probably working on about 10 PRs a day. If you run it serially, it will take about five hours because you’re waiting for each PR CI to pass before running the second one.
The total amount of CI you’ll run is about 50. The real challenge is when you’re in a big team and you’re merging 100 PRs a day. If it takes the same amount of CI, now we are looking at completing about 50 hours. Can we do better?
Batching changes
One way we can think about doing this better is by batching changes. Instead of merging one PR at a time, what your system can do is it can wait for a few PRs to get collected before running the CI. The advantage here is you’re creating these batches which essentially make sure that you’re reducing the number of CIs that you’re running, but essentially it helps reduces the wait time.
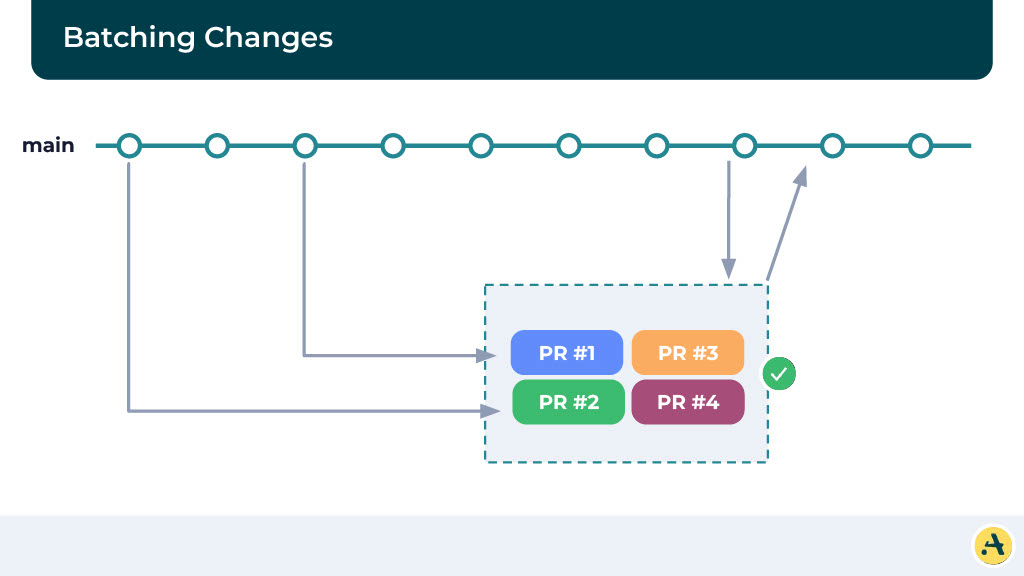
If the CI passes, it’s going to merge all four of the PRs together, and all of them should eventually pass the build. And in case there’s a failure, we are going to bisect these batches so that we can identify which PR is causing the failure and merge the rest of them. Here is where you can imagine it’s going to cause a little bit of a slowdown in the system.
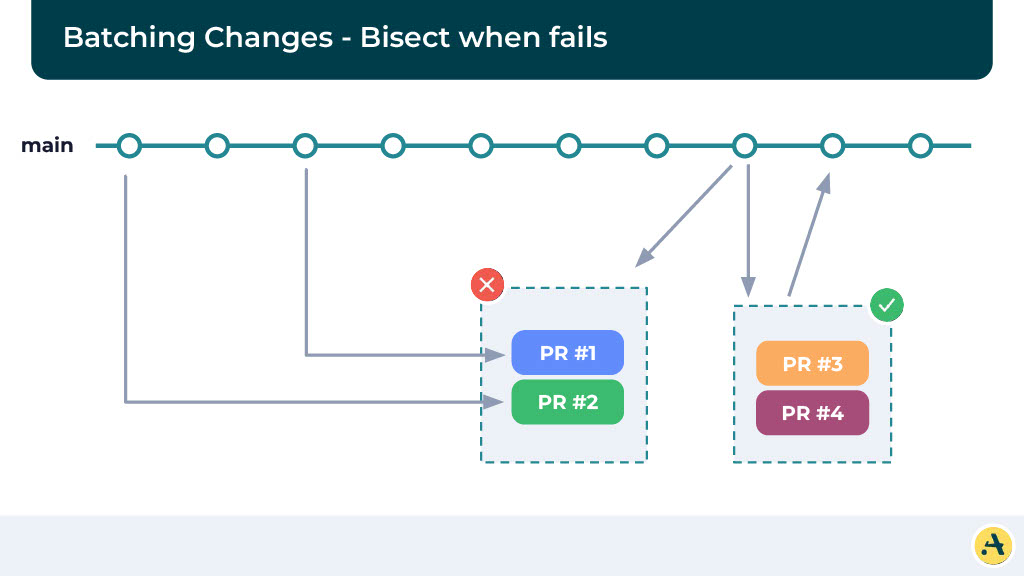
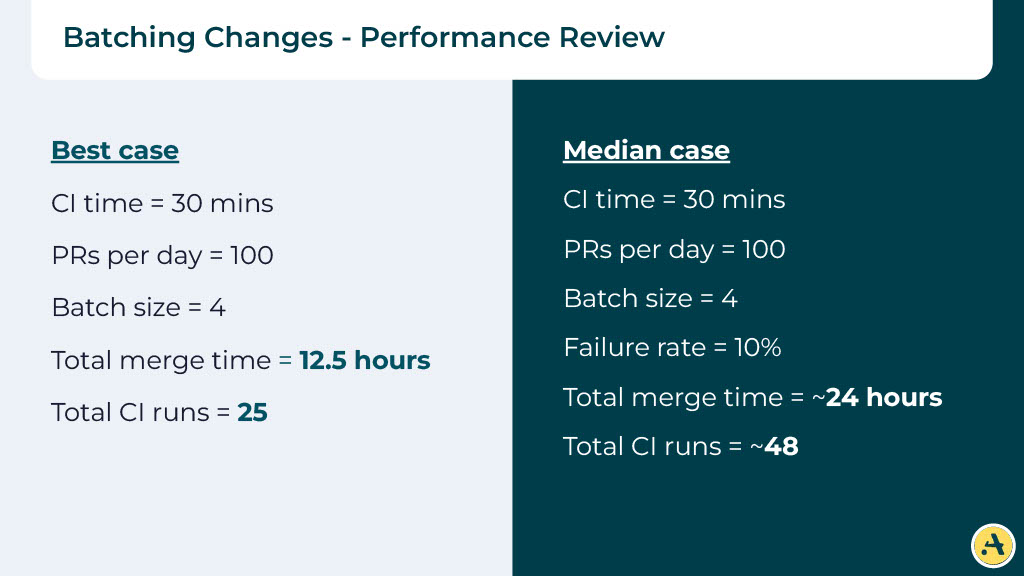
Let’s consider the numbers. If there is no failure, and you’re doing a batch size of four, now your total merge time suddenly drops from 50 hours to 12.5 hours. That’s a significant improvement! Also, the total number of CI runs is going to be small.
But in a real scenario, you’re going to have failures. If there is even a 10% failure rate, you’ll see the merge time increases significantly. You could be waiting upwards of 24 hours for all your PRs to merge. Not to mention the number of CIs also increase significantly.
Can we do better still?
Instead of thinking of mergers happening in a serial world, let’s think of them as parallel universes. If you think of the main as not a linear graph or a linear path, you think of this as several potential futures that the main can possibly represent.
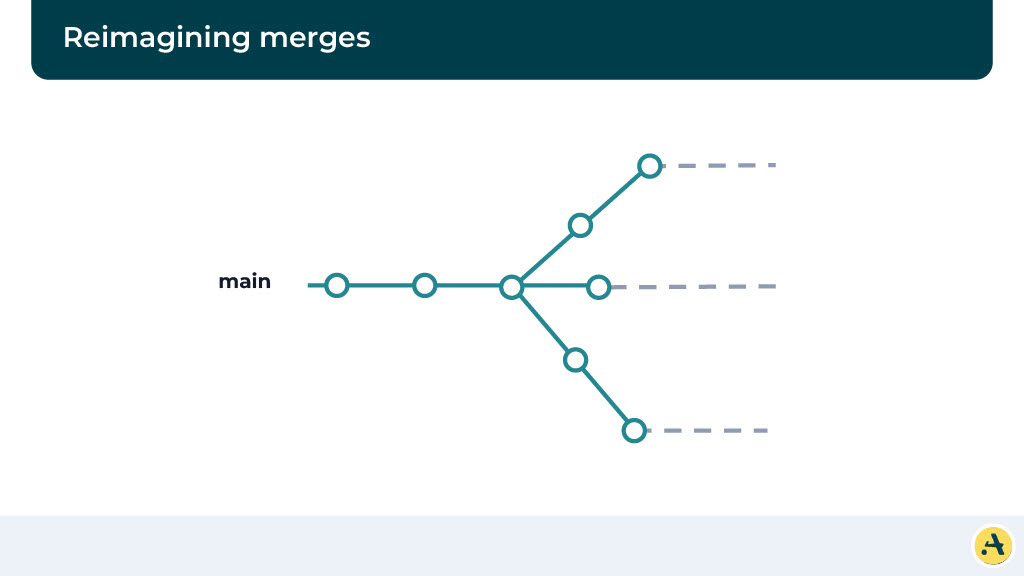
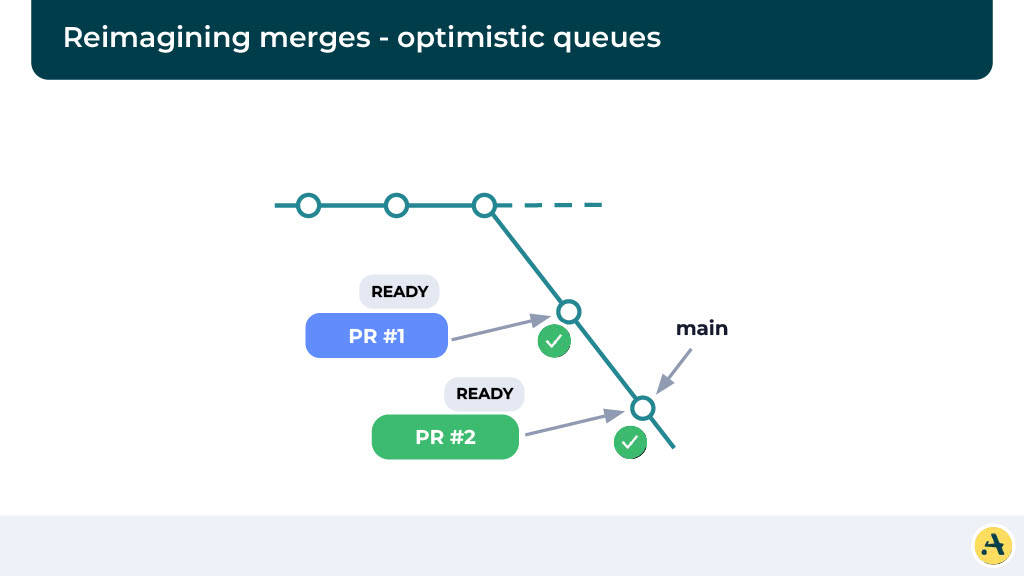
To give you an example, let’s think about the optimistic cues. Let’s say your main is at this particular point, a new PR comes in, and it’s ready to merge. So what we are going to do is something similar to before, we’re going to pull the latest mainline and create this alternate main branch where we run the CI. While the CI is running, a second PR comes in.
Instead of waiting for the first CI to pass, we optimistically assume that the first PR is going to pass, and in this alternate main, we’re going to start a new CI with the second PR. Once the PR for the first one passes, it’s going to eventually merge. And likewise, as soon as the CI for the second one passes, it’s going to merge.
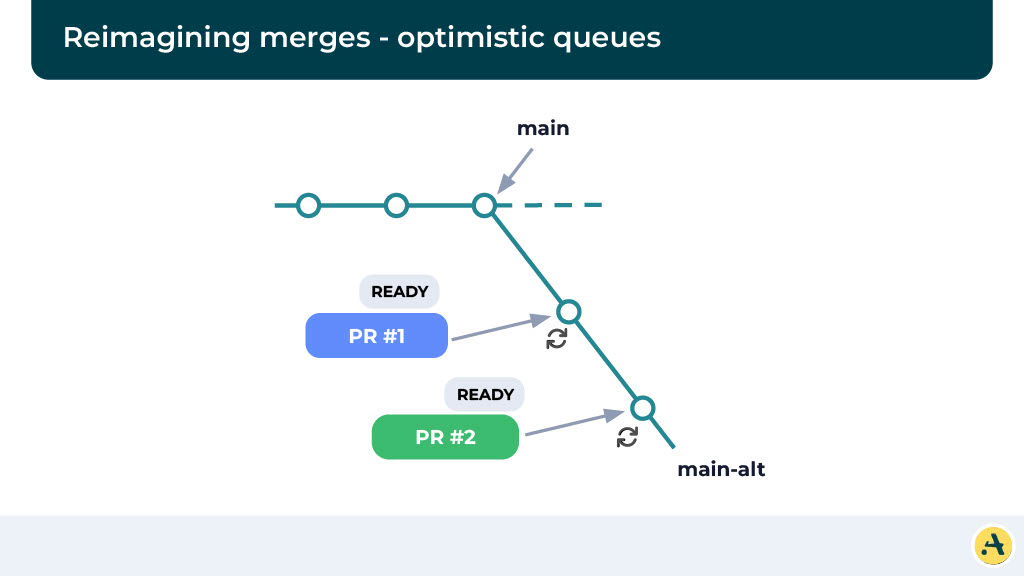
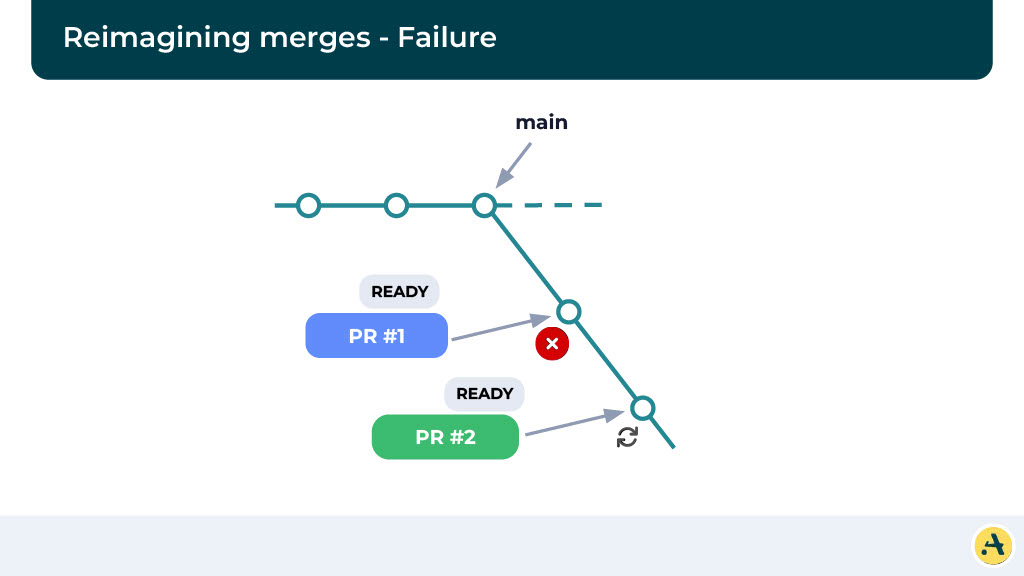
Now obviously here we’re looking at what happens if the CI for the first one fails. The CI for the first one fails is going, what we’re going to do is we’re going to reject this alternate main and essentially create a new alternate main where we’re going to run the rest of the changes and follow the same pattern. And in this particular case, we are going to make sure the PR1 does not merge and cause a build failure.
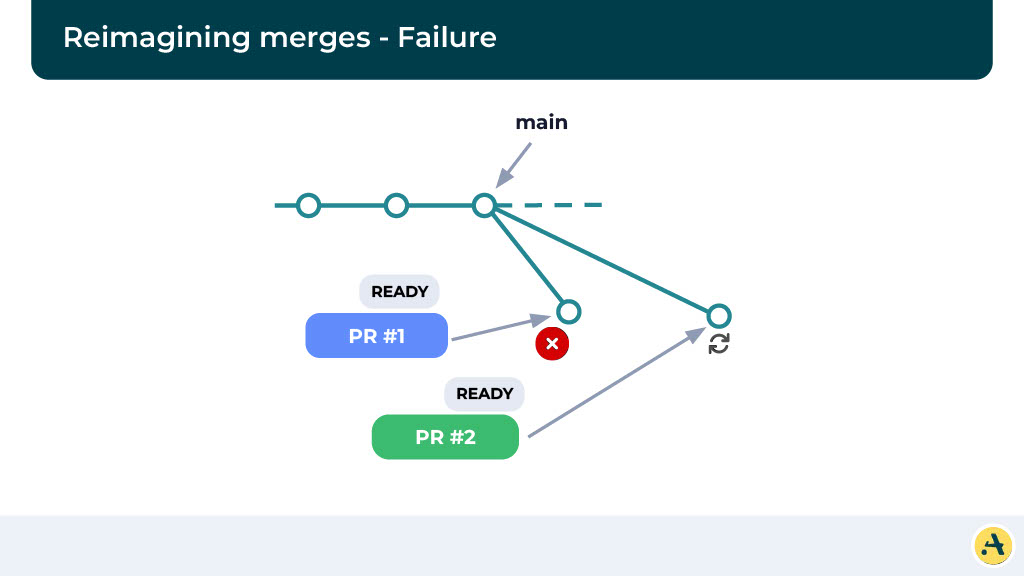
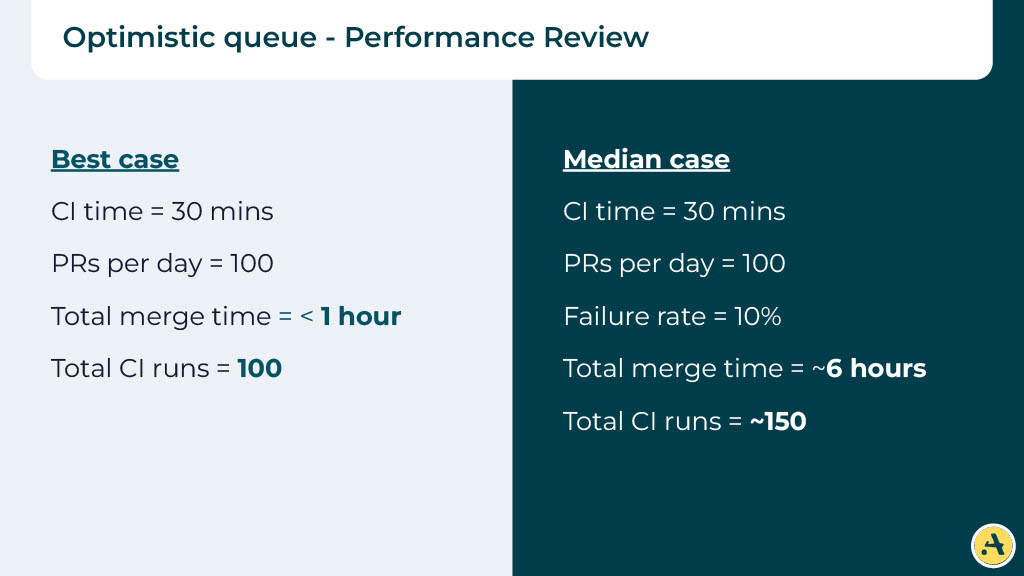
Looking at the numbers (again)
So in the best of worlds, given that we are not waiting for any CI to finish, you can technically merge all 100 PRs in less than an hour. Obviously, in a median case where we expect 10% of the PRs to fail, your merge time is still very reasonable. Now you’re merging in 6 hours instead of the 12.5 hours that we were seeing before.
Combining strategies
One way to merge even faster is by combining some of the strategies we’ve already discussed. If you combine optimizing the queue with batching, you should see decent returns. Instead of running a CI in every PR, now we combine them together. Essentially, you’re running these batches of PRs and again, as they pass, you merge them. If they fail, you split them up and identify what causes the failure.
Predictive modeling
Now we are saying the total immersed time is still less than one hour, but what we have done is we have reduced the total number of CIs to 25 instead of 100. And even in the median case, we decreased from six hours to four hours and your total number of CIs is still lower.
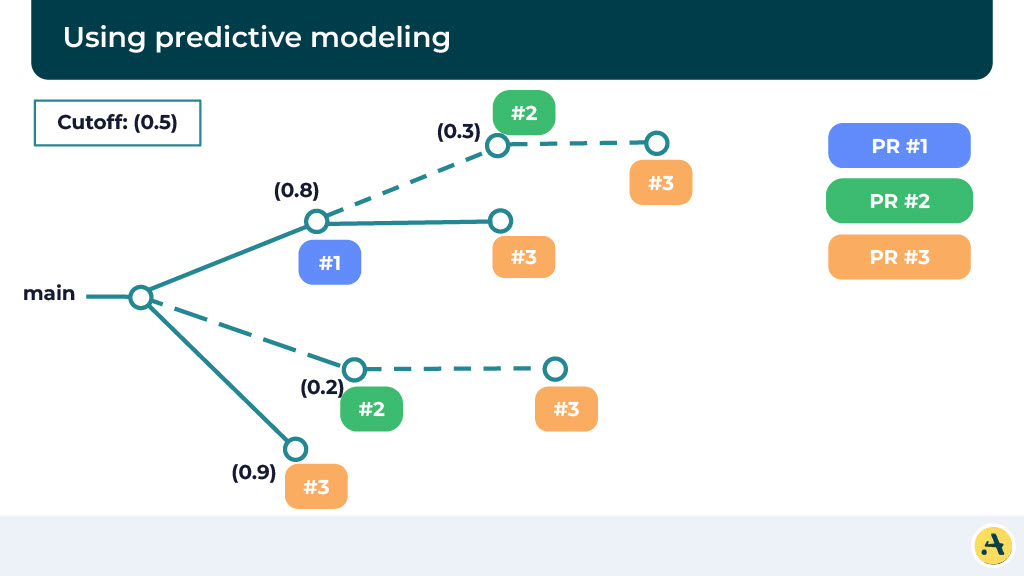
Now let’s think about some more concepts here. One of the concepts is predictive modeling, but before that, let’s think about what happens if we assume all possible scenarios of what the main code looks like if a particular CI is going to pass or fail or PR is going to pass or fail.
So in this case, we’ve represented these three PRs and all possible scenarios where all three of them merge, one of them merge, or two of them merge. And essentially if you run in this way, then we never have to worry about failures because we’re already running all possible scenarios and we know one of them is going to be successful.
Although the challenge here is obviously running a lot of CI. We don’t want to be running too much CI, and this is where it can be interesting. So instead of running it on all of them, what we can do is we can calculate a score, and based on that, essentially identify which paths are worth pursuing. So you can do optimization based on lines of code and PR, types of files being modified, tests added or removed in a particular PR, or a number of dependencies.
Here, we have specified the cutoff as 0.5, and as you can see, we are running only a few of these builds, thereby reducing the number of CI.
Multi-queues
Multi-queues are applicable in cases where we can understand different builds. Instead of thinking of this as a singular queue, now we are going to think of this as many different paths you can take and many disjoined queues that you can run.
To do that, we use this concept called affected target. There are systems like Basel that actually produce these results or these affected targets. So essentially if you can identify what builds within your primary repository that a particular change impacts, you can create disjoined queues where all these queues can be independently run while making sure your builds are not impacted.
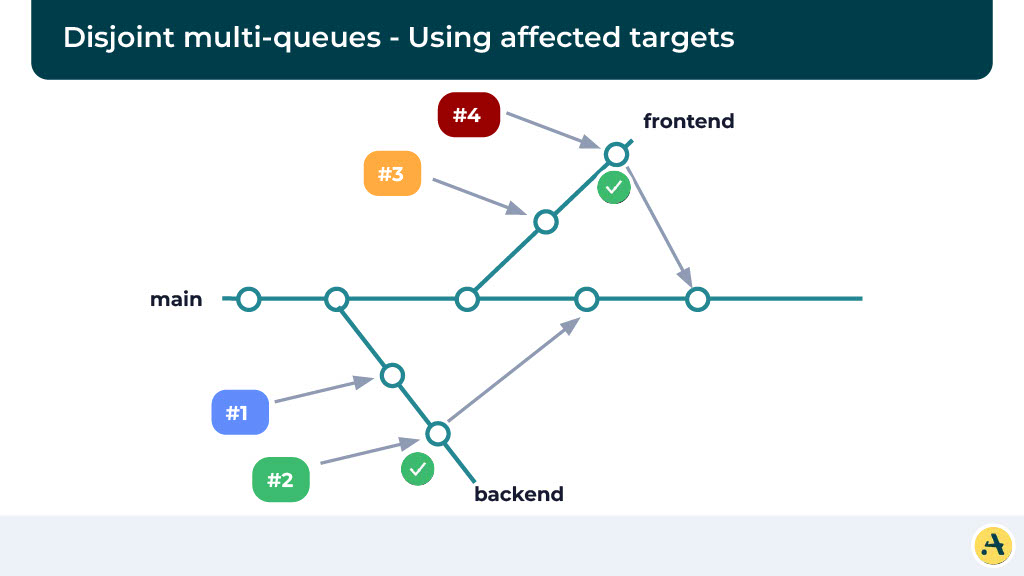
Let’s assume that there are four different kinds of builds that your system produces: A, B, C, and D, and this is the order of the PRs that they came in.
Four queues
Let’s say the PRs that impact A are in the first queue, the PRs that impact B are in the second queue, and so on. One thing to note here is a PR can be more than one queue if it’s impacting more than one target, and that’s totally fine.
Essentially, for PR four or PR five to pass, you need to wait for PR two to pass or fail. But at the same time, we are still making sure that in a worst-case scenario where a PR fails, we are not impacting all the PRs in the queue, but only the ones which are behind that particular queue. This definitely increases the velocity at which you’re merging the changes because it’s in some ways, localizing failures to a particular affected target.
This is a great example where we are looking at two separate queues. Let’s say one target is backend, one target is frontend, and there are multiple PRs queued, but they can independently be compiled and run while making sure that one change is not impacting the other one. And that way you can run them parallelly as well as while not impacting the builds.
Further optimization
There are a few other concepts that we can think about to actually further optimize these workflows. So one of them is thinking about reordering changes. For instance, you can select the high-priority changes or the changes where there’s lower failure risk and put them ahead in the queue. The advantage here is it’s not going to cause a possible chain reaction of failures and it’s going to reuse the amount of possible failures you can have.
But you can also order it based on priority. Something which is a really big change, you can probably say it’s going to be a lower priority and we are going to pick it up later. There are other concepts of, for instance, fail fast. So you can reorder the test execution. For the ones which typically fail more often, you’d probably want to run it sooner. That way as soon as the PR gets queued, you identify these failures and are able to fail fast.
The other thing you can do is you can split the test execution. This is what many companies do, where they will run many of the fast tests before merging and making sure these are the ones that are more critical or things which possibly fail more often, and then run the smoke test or things which typically are stable but maybe slower, but you run them after they’re merging. Obviously, you expect the steps you’re running after the merge to fail very, very rarely, but if it fails you can just roll back.
So essentially you’re trying to find the best of both worlds to make sure your builds are generally passing, and very rarely if it fails, you have a way of automatically rolling it back.
Note: This post was originally delivered as a talk at Conf42.